2023/03/31 追記「MSDASQLでの接続(64ビット版の場合)」
CSVファイルの読み込み

1.背景
オフラインの設備等からの情報は、CSVファイルとして出力されるものが多いようです。これは、CSV(Comma Separated Value =カンマで区切った値)であれば幅広い処理機・処理アプリで対応できるという「互換性の高さ」があるからです。Excelも例外では無く、普通に「ファイルを開く」でCSVを指定すれば開きますし、CSV形式でファイル保存も可能です。
「CSVファイルのVBAでのExcel読み込み」については他の多くのサイトで扱っていますので、今回はVBAで「CSVを読み込む」にはどの様な方法があるか、について軽く紹介したいと思います。
2.システムの概要
CSVファイルのサンプルとして、非常に簡単な図2-1を用意(添付ファイルの it-csv-01.csv)しました。値の区切り(delimiter)としてカンマ式やTAB式などがありますが、今回はカンマとしました。尚、最下行の下に2行ほど空行が入ってます。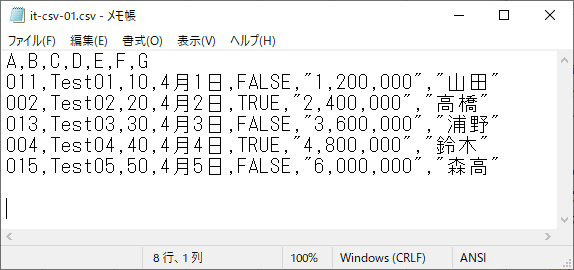
図2-1
そのCSVファイルをダイアログのWebBrouserにドラッグ&ドロップすると、シート上の選択セルを左上とする範囲にデータを書き込むことにしました。このWebBrouserを使う方法は「ファイルの存在有無の確認が不要」であるのと、「データをシート上の任意の位置にダウンロードできる」ことから選びました。
(実際にはデータを配列にし、内部処理する流れになると思います。)
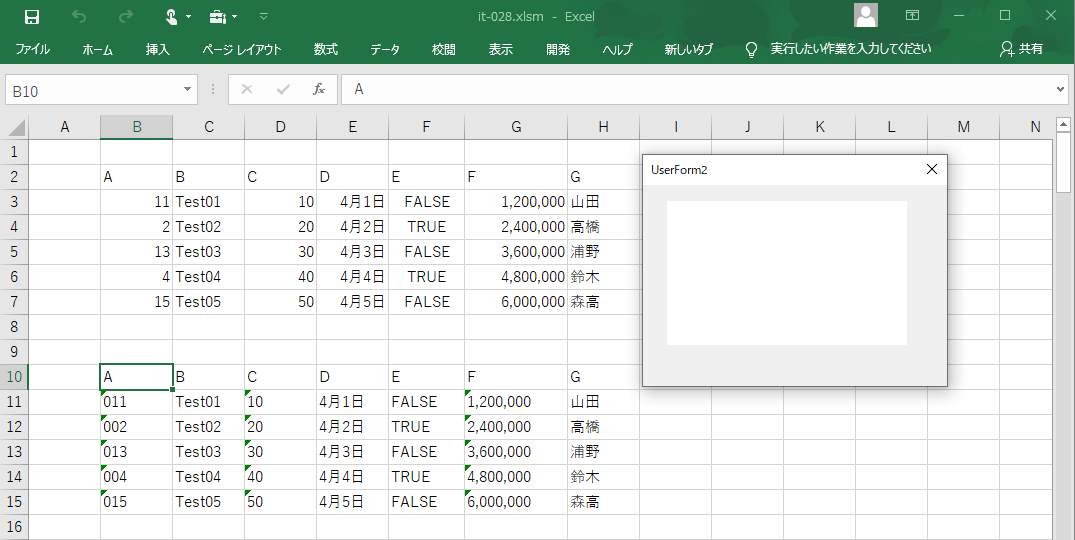
図2-2
ちなみに、Range("B2:H7")は「csvをデータベースに見立ててアクセスする方法」、Range("B10:H15")は「csvを文字の並びとして取り出す方法」による結果です。下側は、セルの左上に緑三角印がついている通り、「文字列」扱いになっています。
この辺の違いについても整理していきます。
3.手法1(データベースとしてCSVを呼び出す)
3-1.フォームの作成
ここではCSVファイルを取得する手段として、フォーム上に「WebBrowserコントロール」を配置し、そこにSCVファイルをドラッグ&ドロップすることでファイル名を取得させています。但し、標準状態のツールボックスには「WebBrowser」がありませんので、ツールボックス上のマウス右ボタンで「その他のコントロール」を選択し、一覧の中から「Microsoft Web Browser」を選択します。(図3-1)
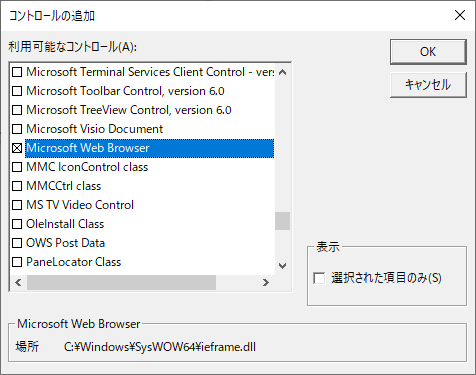
図3-1
するとツールボックスに「WebBrowser
 印」が追加されますので、それをクリックしフォーム上に「WebBrowserコントロール」を配置します。(図3-2)
印」が追加されますので、それをクリックしフォーム上に「WebBrowserコントロール」を配置します。(図3-2)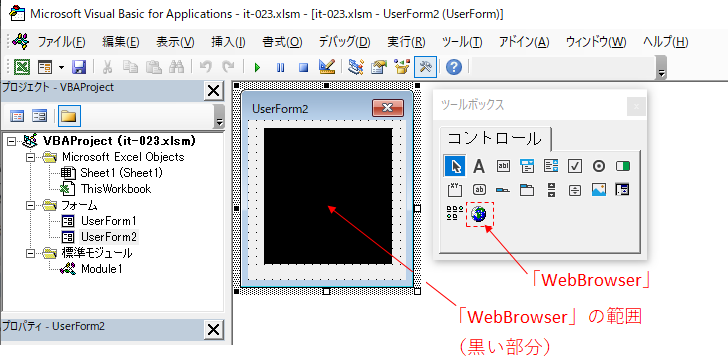
図3-2
尚、WebBrowser等のコントロールについては、当サイト内の下記項目も参考にして下さい。
「画像を直接シートに貼り付ける」
「あらゆるデータファイルをシートに貼り付ける」
「回転させた画像をシートに貼り付ける」
3-2.フォームのコード
フォームのWebBrowserにCSVファイルをドロップした時に発生するイベントを使用し、CSVデータを取り出してシートに貼り付けるのが図3-3です。一番下のサンプルファイル(it-028.xlsx)ではUserForm1の内容になります。
- '========== ⇩① データベースとしてCSVを呼び出す(UserForm1) ============
- Private Sub WebBrowser1_BeforeNavigate2(ByVal pDisp As Object, URL As Variant, Flags As Variant, TargetFrameName As Variant, PostData As Variant, Headers As Variant, Cancel As Boolean)
- Dim cn As Object
- Dim rs As Object
- Dim Path As String '←URLのファイル名の無いPathを代入する変数
- Dim Fname As String '←ファイル名を代入する変数
- Dim SQL As String '←SQL文の変数
- Dim Temp() As Variant '←CSVの値を入れる配列
- Cancel = True
- Path = Left(URL, InStrRev(URL, "¥"))
- Fname = Mid(URL, InStrRev(URL, "¥") + 1)
- SQL = "Select * from [" & Fname & "] "
- Set cn = CreateObject("ADODB.Connection")
- Set rs = CreateObject("ADODB.Recordset")
- cn.Provider = "Microsoft.ACE.OLEDB.12.0;"
- cn.ConnectionString = "Data Source=" & Path & ";Extended Properties='Text; HDR=Yes';"
- cn.Open
- rs.Open SQL, cn
- ReDim Temp(0 To rs.Fields.Count - 1, 0 To 0)
- For i = 0 To rs.Fields.Count - 1
- Temp(i, 0) = rs.Fields(i).Name
- Next i
- Do Until rs.EOF
- cnt = cnt + 1
- ReDim Preserve Temp(0 To rs.Fields.Count - 1, 0 To cnt)
- For i = 0 To rs.Fields.Count - 1
- Temp(i, cnt) = rs(i).Value
- If IsNull(Temp(i, cnt)) Then Temp(i, cnt) = ""
- Next i
- rs.movenext
- Loop
- Selection.Resize(UBound(Temp, 2) + 1, UBound(Temp, 1) + 1).Value = _
- Application.WorksheetFunction.Transpose(Temp)
- rs.Close
- cn.Close
- Set rs = Nothing
- Set cn = Nothing
- End Sub
WebBrowserコントロールにドロップされたファイルは、2行目の「BeforeNavigate2イベント」で受け取ります。その引数の内の「URL (As Variant)」でファイル名が取得できます。
3~8行目は、プロシージャ内で使用する変数の宣言です。CSVファイルの値は8行目のTemp配列に格納していきます。
10行目の「Cancel = True」は、ドロップしたファイル内容をこのWebBrowserで表示させない(Cancel)ようにするものです。
12~13行目では、ドロップされたファイルのパス+ファイル名として受け取った引数URLを、「パス名」と「ファイル名」に分解します。式内の「InStrRev(URL, "¥")」は、「文字列URLに対して¥の字の位置を後ろ側から探す」というものです。
探し当てた「¥」は、「パス名」と「ファイル名」を分けている部分に当たりますので、その位置を基準にして前側をパス名に(12行目)、後ろ側をファイル名に(13行目)にしています。
14行目は、SQL文を作っています。「CSVファイル = データベーステーブル」に見立てていますので、ファイル名(13行目で作った変数Fname)がテーブルになり、そのテーブルから全てを取り出しますので「Select * From テーブル名」としています。 テーブル名はカギカッコ( [ ] )で囲みます。
16~17行目で、ADO(ActiveX Data Objects)の接続( = connection)と読み取り( = Recordset)のオブジェクトを生成し、19行目でプロバイダーを、20行目で接続文字列を設定します。
20行目の接続文字列の内「Data Source」には、RDB(リレーショナルデータベース)で言うところのデータベースである「パス名(12行目で作った変数 Path )」を設定し、「Extended Properties」にはデータベースの種類である「Text」を設定します。
その後ろについている「HDR=Yes」ですが、HDR(Header Label 又は Header)は「1行目をカラム名として扱う」か否かの設定です。Yes(=扱う)が既定値ですので、省略して「Extended Properties=Text;」でも同じ事になります。
「1行目もデータとして扱いたい」場合には、「HDR=No」として20行目のようにTextと一緒にシングルクォーテーション(又はダブルクォーテーションを2連)で囲みます。これは両方ともExtended Propertiesの項目だからの様です。
22行目ではConnectionを開き、23行目では実行するSQL文と接続しているConnectionオブジェクトを引数にしてrecordsetを開きます。
24~27行目では、配列Tempにカラム名を代入しています。
ここまで来ると、20行目のExtended Properties に「HDR=No」として「1行目もデータと見なして一緒に取得できるのではないか」と思われると思います。しかし、この方法はうまく行きませんでした。
原因は「CSV1行目とCSV2行目以降のデータ型が異なる」ために、CSV2行目以降のデータ型が数値(TypeがadInteger型)の場合にCSV1行目の文字列がNull値になってしまうのです。
例えば今回の場合CSVファイルの1列目と3列目についてはCSV2行目以降は全て数値ですので、そのカラム名である「AとCの文字が表示されない(=消えてしまう)」ことになります。
以上の理由で、CSVデータの全てが文字列(数値と見なされるものが無い)であったり、カラム名がデータ側(CSV2行目以降)と同じデータ型である場合以外は、「HDR=No で1行目も一緒に取得」する方法はうまく行きません。
尚、列のデータ型を文字列相当(adVarWChar型)に強制的に変更しようとも試みましたが、こちらもうまく行きませんでした。
一方、カラム名の行が無い(=CSVファイルの1行目からデータ)場合は、注意が必要です。
例えば1行目のデータが「123.567」の様な小数点のある数値の場合、上記のコードでは「123.567をカラム名と見なす」ことになります。すると「123#567」のように「小数点が#印に置き換わる」現象が発生します。
これではデータになりませんので、「HDR = No」とした上で25~27行目のカラム名を配列に代入する代わりに「Temp = rs.GetRows」で全データを取り込む方法が良いと思います。
ですので24~27行目で、「わざわざカラム名を取り出して、配列Tempに代入する」作業をする事でCSVファイルの1行目を書き出しています。
コードの内容としては、24行目のRedimで配列TempのサイズをCSV1行目が入るサイズに変更しています。CSV2行目以降もデータを同じ配列Tempに入れていきます(=Redimでサイズを大きくしていく)ので、延ばしていく次元を2次元側にしています。行列から見ると縦横がひっくり返っていますので、最後貼り付ける段階(40行目)で縦横を入れ替えます。
29~37行目は、CSV2行目以降のデータ本体部分を配列に入れていきます。
まず31行目で配列Tempのサイズを1列増やしています。1次元目の「0 To rs.Fields.Count - 1」は24行目と同じですが、2次元目の「0 To cnt」でDo~Loopが回るたびにcntが1つずつ増えていきます。
配列サイズを広げた後、32~35行目のFor~NextをCSVファイルの列数分だけ回し、33行目で1つずつ配列に代入します。
但し代入した値がNullの場合があります。このNullが配列に存在すると、40行目の「Transpose関数」で行列を入れ替える時にエラーが発生しますので、34行目でゼロ文字に置き換えます。
CSVファイルの1行分の処理が終わると、36行目で「movenext」を実行し、CSVファイルの次の行に移り処理を繰り返します。
CSVファイルの全行の処理が完了すると EOF(End of File)となりますので、29行目の「Until rs.EOF」でDo~Loopから外れます。
40行目で配列Tempの行列を入れ替え、それをシート上に貼り付けます。
貼り付ける範囲は貼りつける配列サイズと合っていないとエラーが発生しますので、配列TempのサイズをUbound関数で割り出してResizeで範囲サイズを変更します。
ここで「.Resize(UBound(Temp, 2) + 1, UBound(Temp, 1) + 1)」と、行・列ともに「+1」しているのは、行列入れ替えをする前の配列Tempですのでインデックスがゼロから始まっているために「+1」する必要があります。
尚、「Transpose関数」で行列入れ替えをした後は、インデックスは必ず1からになります。
最後に、42~43行目で「recordset」「connection」を閉じ、44~45行目でオブジェクトを開放します。
得られたシート上の値は、図3-4の様になります。
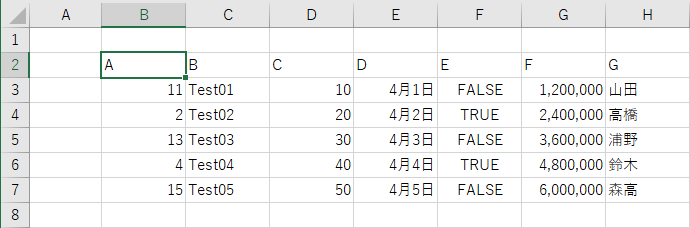
図3-4
どの列もデータ型が正しく貼り付けられています。但し、1列目は「011」などと「ゼロで埋めて3桁にする」意図でしたが、ゼロは取れてしまい通常の数値に置き換わってしまいました。あらかじめ書式が分かっていれば、貼り付ける前に書式を揃えることが出来るかと思います。
尚、19~20行目では、プロバイダとして「Microsoft.ACE.OLEDB.12.0」を使用しましたが、代わりのプロバイダとして「MSDASQL」を使用することも可能です(図3-5)。但しその際には接続ワード(20~21行目)も変更になりますので、必ずペアで変更させて下さい。
- cn.Provider = "MSDASQL"
- cn.ConnectionString = "Driver={Microsoft Text Driver (*.txt; *.csv)};" _
- & "DefaultDir=" & Path & ";"
また、上で説明した「プロバイダとしてACEを使用した時に、1行目もデータと見なす HDR=No 」の役目は、図3-6の様に「FirstRowHasNames=0」を接続文字列に指定するのですが、バグのために無視されてしまいます。
- cn.Provider = "MSDASQL"
- cn.ConnectionString = "Driver={Microsoft Text Driver (*.txt; *.csv)};" _
- & "DefaultDir=" & Path & ";FirstRowHasNames=0; "
よってプロバイダとしてMSDASQLを使用した時は、先頭行は必ずフィールド名として扱われる(= CSVの1行目は読み込めない)ことになります。ですので1行目を読み込むためには25~27行目が必要となります。
ここで、Excelが使用できるプロバイダの種類(図3-7)と、データベース対象別の接続文字列(図3-8)について下記にまとめました。今回の「CSVファイルをデータベースに見立てる」場合は、図3-8のTXTの部分になります。
| OLEDBプロバイダ | ADODB.Connection.Provider= |
|---|---|
| Ace | "Microsoft.ACE.OLEDB.12.0;" |
| MSDASQL | "MSDASQL" |
| OLEDBプロバイダ | 対象データソース | ADODB.Connection. |
|---|---|---|
| Ace | Access | "Data Source=[ファイルパス];" |
| Excel | "Data Source=[ファイルパス]; Extended Properties=""Excel 12.0;"" | |
| TXT | "Data Source=[ディレクトリパス]; Extended Properties=Text" | |
| MSDASQL | Access | "Driver=Microsoft Access Driver (*.mdb, *.accdb);DBQ=[ファイルパス];" |
| Excel | "DSN=Excel Files;DBQ=[ファイルパス];" または "Driver={Microsoft Excel Driver (*.xls, *.xlsx, *.xlsm, *.xlsb)};DBQ=[ファイルパス];" | |
| TXT | "Driver={Microsoft Text Driver (*.txt; *.csv)};DefaultDir=[ディレクトリパス];" |
|
[2023.03.31 追記] なお、Excelの64ビット版を使用している場合には、図3-5や図3-6ではエラーが発生します(私のPCではExcelがダウンしてしまいました)。これはDriverとして指定している「Microsoft Text Driver」が、64ビット版には存在しない為です。 他サイトではドライバーを入れる等の対策が紹介されていますが、コントロールパネルの「ODBCデータソースのセットアップ」を確認してみると、図3-9のようになっています。左側が32ビット版、右側が64ビット版です。 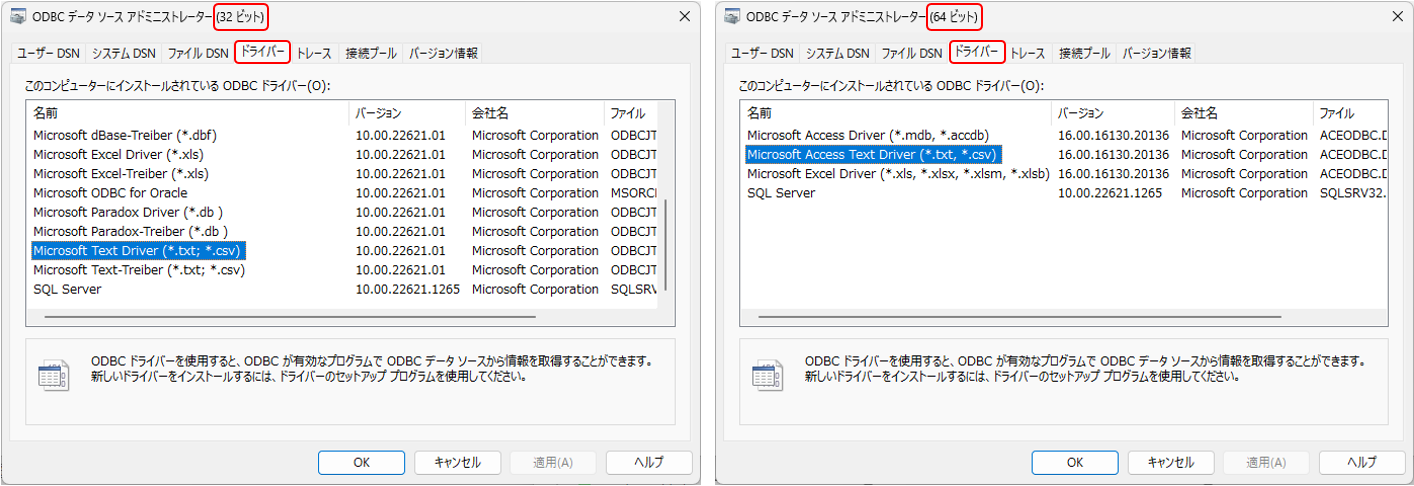 図3-9 図3-5と図3-6で使っていた「Microsoft Text Driver」は、左側の32ビット版には確かにありますが、右側の64ビット版の方には見当たらない事が分かります。その代わりに似ているものとして「Microsoft Access Text Driver」というのがあります。 そこでこの「Microsoft Access Text Driver」をドライバーとして使用したのが図3-10です。
64ビット版の場合、この図3-10を使用すると正しく動くことが確認できました。なおカッコ内の「*.txt」と「*.csv」を区切っているのは、32ビット版では「;(セミコロン)」でしたが、64ビット版では「,(カンマ)」になりますので注意が必要です。 なお、32ビット版と64ビット版が混在している環境で同じマクロを使用しなければならない時は、標準モジュール宣言部で「#If Win64 then ~ #Else ~ #End If」を使用してモジュール定数を変更し、流すコードを分岐する等が必要です。 なお、どのPCにも「Microsoft Access Text Driver」が存在するかまでは確認できていません。少なくともOfficeの32ビット版がインストールされている私の古いPCには存在しませんでした。もし当ドライバーが入っていない場合は、当然ながらこの手法は使えません。 |
なお、このデータベースとしてデータを扱う方法としては、下記項目も参考にして下さい。
「Excelシート上にいDBを作り、SQLを使ってデータを入出力する」
「ExcelシートDBを使った会議室予約システム」
4.手法2(StreamオブジェクトでCSVを呼び出す)
フォームの作成については、3-1項と同じで、WebBrowserコントロールを使用しています。フォームのコードについて、図4-1で説明していきます。また自作関数mySplitを使って1行のデータを個々のデータに分割していますが、それについては図4-6で説明します。
4-1.手法2の本体部分
- '========== ⇩② StreamオブジェクトでCSVデータを呼び出す(UserForm2) ============
- Private Sub WebBrowser1_BeforeNavigate2(ByVal pDisp As Object, URL As Variant, Flags As Variant, TargetFrameName As Variant, PostData As Variant, Headers As Variant, Cancel As Boolean)
- Dim st As Object '←Streamオブジェクト
- Dim buf As String '←CSVデータを丸ごと入れる変数
- Dim buf1() As String '←CSVデータを改行印で区切る1次元配列
- Dim buf2() As String '←CSVデータを更にカンマ印で区切る2次元配列
- Dim buf_row As Variant '←CSVの1行分をカンマで分割した1次元配列
- Dim CharS As String '←CSVファイルの文字コード
- Dim CSV_row As Long, CSV_col As Long '←csvファイルの行数・列数
- Dim i As Long, j As Long '←カウンター変数
- Cancel = True
- Set st = CreateObject("ADODB.Stream")
- CharS = "shift-jis" '←csvファイルの文字コード(UFT-8の場合は "utf-8"に変える)
- st.Charset = CharS
- st.Open
- st.LoadFromFile URL
- buf = st.ReadText
- st.Close
- While Right(buf, Len(vbCrLf)) = vbCrLf
- buf = Left(buf, Len(buf) - Len(vbCrLf))
- Wend
- buf1 = Split(buf, vbCrLf)
- CSV_col = UBound(Split(buf1(0), ","), 1)
- CSV_row = UBound(buf1, 1)
- ReDim buf2(0 To CSV_row, 0 To CSV_col)
- For i = 0 To CSV_row
- buf_row = mySplit(buf1(i), ",")
- For j = 0 To CSV_col
- buf2(i, j) = buf_row(j)
- Next j
- Next i
- Selection.Areas(1).Item(1).Resize(UBound(buf2, 1) + 1, UBound(buf2, 2) + 1) = buf2
- Set st = Nothing
- End Sub
49~56行目は、プロシージャ内で使用する変数宣言です。
この手法2では「Streamオブジェクト」を使用しますので、それ用のオブジェクト変数を49行目で準備します。
57行目は、ドロップしたファイル内容をWebBrowse上で表示させないようにします。
59行目では「Streamオブジェクト」を生成します。
61行目では変数CharSにCSVファイルの文字コードを文字列として代入し、62行目でStreamオブジェクトのCharsetプロパティに設定しています。
ここでは文字コードとして「shift-jis」をセットしていますが、対象のCSVファイルが「UTF-8」であるならばその文字列に変更して下さい。
しかし、文字コードが決まっていない(=色々な文字コードのCSVファイルを扱う)場合には、固定する訳にいきません。文字コードには非常に多くの種類がありますが、残念ながらExcelには判別関数のような便利なものはありません。
そこで、他のサイトで多々紹介されている判別関数のコードをコピーし、その戻り値を61行目のCharSに代入してもらえれば良いような形にしました。
64行目のOpenメソッドでストリームオブジェクトを開き、65行目でドロップしたCSVファイルの内容をストリームに読み込みます。
そのストリームに読み込んだCSVファイルから文字を読み取ります。ReadTextメソッドには読み取る文字数のパラメータを指定できますが、ここでは指定していません(=既定のAdreadall)ので全文字を読み取り、変数bufに代入します。
読み取りが完了したら、67行目でストリームを閉じます。
69~71行目は、「CSVファイルの末尾の空行を削除」しています。
空行が何行か有るということは「改行(=vbCrLf)が何個か連なっている」ことになりますので、「ファイルの後ろ側から、改行を切り取る」ことを「一番後ろの改行が無くなるまで」続ければ良い事になります。
そこで今回は、While~Wendを使用しました。このWhileの後ろに続く条件式が成り立っている(True)間は70行目を実行するものです。
良く使われるDo While~Loop と内容は同じですが、途中で抜け出す方法(Do~Loop ならExit Do )が無いこともあり、現在ではあまり使われないようです。但し役割だけは覚えておくべきと思い今回使用しました。
なお、Do While~Loop に置き換えると図4-2のようになります。
- Do While Right(buf, Len(vbCrLf)) = vbCrLf
- buf = Left(buf, Len(buf) - Len(vbCrLf))
- Loop
73行目では、改行マーク(vbCrLf)毎にCSVファイルの文字列を分割し、配列buf1に代入しています。
74~75行目は、最終的なCSVファイルの縦横サイズを求めています。74行目は、CSVファイルの1行目(=buf1(0))をカンマで分割し、その列数を算出しています。Split関数で分割したものはインデックスがゼロから始まりますので、この求められたCSV_colに1を足したものが列数になります。(77行目のReDimはインデックスをゼロから始めていますので、あえて1を足していません。)
75行目はbuf1(vbCrLfで分割したもの)の最大インデックスから、最終的なCSVファイルの(ゼロから数えた)行数を求めています。
77行目は、74~75行目で求めた最終的なCSVファイルの縦横サイズから、buf2配列の大きさを指示しています。
79~84行目では、77行目でサイズを確定させたbuf2配列にデータを入れていきます。
79行目では行毎に、81行目では列毎にループをまわします。
80行目の右辺は自作関数mySplitです。イメージとしては図4-3の様なもので、行としてまとまったデータ(buf1(i))と分割する文字列(ここではカンマ)を引数にすると、列数分に分割するものです。
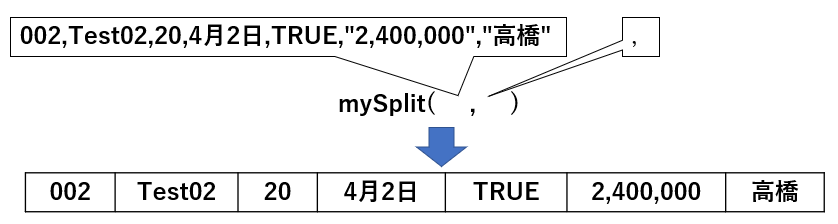
図4-3
これだけだと通常のSplit関数と同じですが「ダブルクォーテーションで囲まれた文字列内のカンマでは分割しない」というのが特徴です。その分割した値は80行目の左辺でbuf_rowに配列として代入されます。
分割のロジックについては図4-6で説明します。
82行目では、その列数分に分割した値(buf_row)を1つずつ取り出してbuf2配列にデータを入れていきます。
なお、79~84行目を図4-4の様なコードでも結果は同じです。buf_row配列を使用せずに、mySplitの結果を直接buf2配列に代入する方法です。
- For i = 0 To CSV_row
- For j = 0 To CSV_col
- buf2(i, j) = mySplit(buf1(i), ",")(j)
- Next j
- Next i
しかし、81~83行目のFor~Nextが回るたびにmySplit関数が呼び出されており、しかも左辺への代入に使用する値は配列の1つだけ、という様に非常に効率が悪い(=処理時間がかかる)事が分かります。
関数の戻り値を複数回使用する場合は、一度変数・配列に代入することで無駄が省けます。
最後に85行目で、選択範囲にCSVデータを貼り付けています。
86行目では59行目で生成したstオブジェクトを開放しています。
得られたシート上の値は、図4-5の様になります。
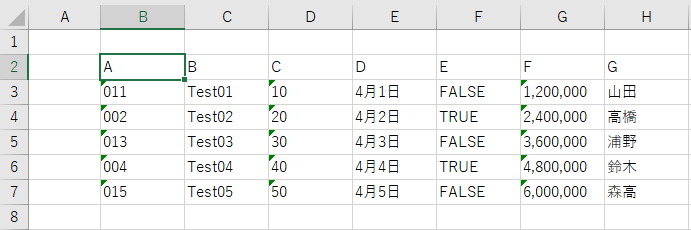
図4-5
手法1と異なり、全列が左寄せ(=文字列の表示)になっています。シート上での計算には支障ありませんが、見栄え的には手を入れる必要があるかもしれません。
4-2.CSVファイルの1行をカンマで分割する関数
図4-1の80行目で使用した「文字列をカンマで区切る」mySplit関数が、以下(図4-6)です。- '==== ⇩③ 1行データをDelimiterで個々のデータに分割(UserForm2、UserForm3) =======
- Function mySplit(buf As String, Delimiter As String) As Variant() '引数:buf=対象文字列 Delimiter=区切り文字
- Const MOJI As String = """" '←文字列を囲っている文字(ここでは「"」)を指定
- Dim MOJI_count As Boolean '←MOJIを数える変数。奇数ならFalse、偶数ならTrue
- Dim SP() As Variant '←1行分のデータをカンマ印で分割した値を入れる配列
- Dim buf1 As String '←bufから切り出した1文字
- Dim buf2 As String '←切り出した文字をまとめた文字列
- Dim i As Long, cnt As Long '←カウンタ変数
- buf = buf & Delimiter
- For i = 1 To Len(buf)
- buf1 = Mid(buf, i, 1)
- If buf1 = MOJI Then
- MOJI_count = Not MOJI_count
- ElseIf (buf1 = Delimiter And MOJI_count = False) Then
- ReDim Preserve SP(0 To cnt)
- cnt = cnt + 1
- SP(UBound(SP, 1)) = buf2
- buf2 = ""
- Else
- buf2 = buf2 & buf1
- End If
- Next i
- mySplit = SP
- End Function
このmySplit関数は、2つの引数を受け取ります。第一引数は対象文字列、第二引数は区切り文字です。
文字列を囲う文字は90行目で「"」に固定していますが、引数にすることも可能です。
90行目は定数MOJIの設定をしていますが、ダブルクォーテーションが4つ並んでいます。両端のダブルクォーテーションは「文字列を囲む印」です。右から2つ目のダブルクォーテーションが「本当のダブルクォーテーション」で、右から3つ目のダブルクォーテーションは「2つ目のダブルクォーテーションを特殊記号では無く、ただの文字としてのダブルクォーテーションとsて認識させるためのエスケープ記号」です。
見た目は4連のダブルクォーテーションなので分かりにくいのは確かです。ですのでASCII文字コードを使って表現す方法もあります。(図4-7)
- Const MOJI As String = Chr(34) '←エラーになります。
- Dim MOJI As String
- MOJI = Chr(34)
ダブルクォーテーションのASCII文字コードは34です。と言って、Chr(34)を4連のダブルクォーテーションと入れ替えてもダメです(エラーが出ます)。定数として設定するものは、数値や文字そのものでなくてはならないからです。
ですので変数として宣言し、Chr(34)を変数に代入する事が必要です。
91~95行目は、この関数の中で使用する変数宣言です。
97行目は、引数の対象文字列の最後にDelimiter(区切り文字=今回はカンマ)を足します。足す理由と共に、この関数の考え方を図4-8で説明します。
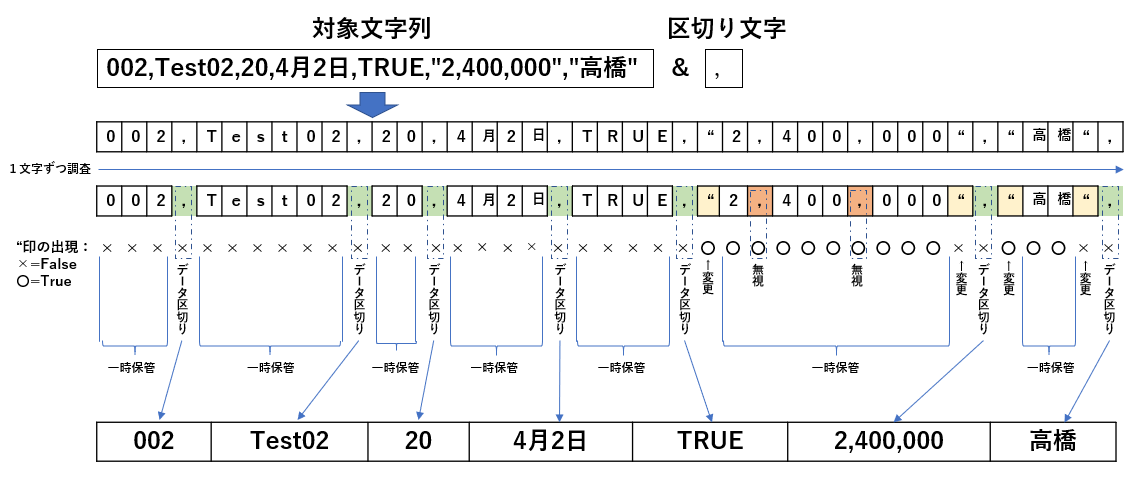
図4-8
対象文字列を先頭から1文字1文字調べて行くのですが、と「ダブルクォーテーション」が現れた時に特別な処理をさせます。
まず「ダブルクォーテーション」が現れた時には、Boolean型変数(ここではMOJI_count )をFalse⇔Trueに切り替えます。変数を宣言した状態ではFalseですので、最初にダブルクォーテーションを見つけたらTrueに変わり、2つ目を見つけたらFalseに変わる、という具合です。
通常の文字の場合は一時保管をしていきますが、「区切り文字」が現れた時にBoolean型変数(MOJI_count )がFalseであれば一時保管していた文字列を配列に代入し一時保管場所をクリアします。
「区切り文字」が現れてもBoolean型変数(MOJI_count )がTrueであれば、それは文字列の中(ダブルクォーテーションで囲まれた中)であるので通常の文字扱いで一時保管していきます。
対象文字列が無くなったら配列を呼出し元に返すのですが、「「区切り文字」出現 + Boolean型変数=False」が配列にデータを代入する条件ですので、97行目のように対象文字列の最後に区切り文字を結合しているのです。
(=最後の区切り文字が無いと、最終列の値が配列に落ちることなく捨てられる事になります。)
なお、ダブルクォーテーションの出現回数をここではFalse・True切り替えで判別しましたが、他サイトでは「ダブルクォーテーションの数を調べ、2で割った余り」で判断させる方法も紹介されています。
自分の腑に落ちるロジックを使えば良いと思いますし、方法は決して1つでは無いので独自のものを編み出してもらいたいと思います。
97行目の対象文字列の最後に区切り文字を足す理由は最後列の値を取り出すため、でした。
そのカンマを足した対象文字列を、99~111行目のFor~Nextで1文字ずつ処理します。繰り返し数は文字数分(Len(buf))です。
まず100行目で1文字を切り出し、その1文字を101行目・103行目・108行目のIf文で仕分けます。
101行目は切り出し文字が「"(ダブルクォーテーション)」であった場合は、「MOJI_count = Not MOJI_count」でMOJI_countのFalse・Trueを逆転させます。宣言段階ではMOJI_countはFalseですので、1回来たらTrue、2回来たらFalseに戻ります。
「"(ダブルクォーテーション)」は文字列を囲んでいるだけですので一時保管もしません。
103行目は、切り出し文字がDelimiter(カンマ)で且つ MOJI_count=False(つまり、ダブルクォーテーションが0回か偶数回)の場合は、値の区切りであると判断され104~107行目が実行されます。図4-8では「データ区切り」という場所です。
同じカンマが来ていても、MOJI_count=True(つまり、ダブルクォーテーションが奇数回)の場合は、ダブルクォーテーションで囲われた文字列の中のカンマと判断されるということです。
実行内容としては、104行目で配列SPを1つ増やし、106行目で配列SPの最大インデックスに溜めておいた文字列buf2を代入します。代入後は、107行目で文字列buf2をクリアします。
108行目はそれ以外の時の処理です。切り出し文字が値そのもの(値中のカンマも含めて)の場合に109行目を実行し、「溜めた値の後ろに切り出し文字を結合していく」という処理をします。
ここで溜めたものが、103行目の条件に合致する(値と値を区切るカンマの時)時に配列に格納される事になります。
尚、97行目で最後にカンマを結合していますが、その最後のカンマの処理(1つの行の中のダブルクォーテーションはゼロ又は偶数のはずなので、MOJI_count=Falseのはず)で最終列の値を配列に書き出してFor~Next文が終了します。
113行目で、値を格納した配列SPを関数の戻り値にして終了します。
5.手法3(FileSystemObjectオブジェクトでCSVを呼び出す)
フォームの作成については、3-1項と同じで、WebBrowserコントロールを使用します。フォームのコードは図5-1となります。また、自作関数mySplitは図4-6と同じものを使用します。
- '========== ⇩④ FileSystemObjectオブジェクトでCSVデータを呼び出す(UserForm3) ==========
- Private Sub WebBrowser1_BeforeNavigate2(ByVal pDisp As Object, URL As Variant, Flags As Variant, TargetFrameName As Variant, PostData As Variant, Headers As Variant, Cancel As Boolean)
- Const ForReading = 1, ForWriting = 2, ForAppending = 8
- '(1=読み込み) (2=書込み) (8=ファイルの最後に追記する)
- Const TristateUseDefault = -2, TristateTrue = -1, TristateFalse = 0
- '(-2=システムの規定値で開く) (-1=Unicodeファイルとして開く) (0=ASCIIファイルとして開く)
- Dim Fso As Object
- Dim OTF As Object
- Dim buf As String
- Dim buf1() As String
- Dim buf2() As String
- Dim buf_row As Variant
- Dim CSV_row As Long, CSV_col As Long 'csvファイルの行数・列数
- Dim i As Long, j As Long '←カウンター変数
- Cancel = True
- Set Fso = CreateObject("Scripting.FileSystemObject")
- Set OTF = Fso.OpenTextFile(URL, ForReading, TristateTrue)
- buf = OTF.ReadAll
- OTF.Close
- While Right$(buf, Len(vbCrLf)) = vbCrLf
- buf = Left$(buf, Len(buf) - Len(vbCrLf))
- Wend
- buf1 = Split(buf, vbCrLf)
- CSV_col = UBound(Split(buf1(0), ","), 1)
- CSV_row = UBound(buf1, 1)
- ReDim buf2(0 To CSV_row, 0 To CSV_col)
- For i = 0 To CSV_row
- buf_row = mySplit(buf1(i), ",")
- For j = 0 To CSV_col
- buf2(i, j) = buf_row(j)
- Next j
- Next i
- Selection.Areas(1).Item(1).Resize(UBound(buf2, 1) + 1, UBound(buf2, 2) + 1) = buf2
- Set OTF = Nothing
- Set Fso = Nothing
- End Sub
117~120行目は、134行目で使用するOpenTextFileメソッドの第二引数・第三引数の値を定数として設定しています。
121~128行目は変数の宣言です。
130行目はCSVファイルをWebBrowserコントロールに表示させないために、Cancel引数にTrue値を代入しています。
132行目では、FileSystemObjectオブジェクトを生成し、変数Fsoに代入しています。
133行目では、FileSystemObjectオブジェクトのOpenTextFileメソッドでドロップしたファイルを開いています。
OpenTextFileメソッドの第一引数はCSVファイルのパス名+ファイル名(引数URL)ですが、第二引数は入出力モード(iomode)、第三引数は開くファイルの形式(format)を指定しています。
実はMicrosoftのサイトでは、構文として「object.OpenTextFile (filename, [ iomode, [ create, [ format ]]]) 」と説明があります。
今回使用していないcreate引数は「ファイルが存在しない場合に新しいファイルを作成できるかどうか」でTrue又はFalseを設定するようなのですが、134行目でcreate引数を(TrueでもFalseでも)設定すると、なぜか正常なデータになりません。
今のところ、データが異常になる原因は調べ切れていません。なにか掴めましたら報告したいと思います。
135行目は、133行目で開いたファイルの全てを読み込み、変数bufに代入します。
136行目では開いたファイルを閉じます。
138行目以降は、手法2と同じため説明を省きます。
また、155~156行目は生成したオブジェクトを解放しています。
出力される値は、手法2の図4-5と全く同じになります。(CSVデータを取り出すところが違うだけなので当然ですが)
なお、133行目の「OpenTextFile」の代わりに「GetFile と OpenAsTextStream」を使っても同様の結果が得られます。
これは、URLで指定した「TEXTファイルを開き、開いたTextSystemオブジェクトを返す」というものです。(図5-2)
- Set OTF = Fso.GetFile(URL).OpenAsTextStream
6.手法のまとめ
以上、3つの手法を紹介しましたが、これをまとめてみると図6-1のようになります。| 手法1 | 手法2 | 手法3 | |
|---|---|---|---|
| データの扱い | データベース上のフィールド値 | 文字列 | |
| 使用オブジェクト | ADODB.Connection ADODB.Recordset | ADODB. Stream | Scripting. FileSystemObject |
| 各フィールドの分割 | 不要 | 必要(区切り文字、文字列囲み文字による処理要) | |
| 対象文字コード | Shift-JISのみ | なんでもOK Charsetで設定 | Shift-JISのみ |
| 出力されるデータ型 | データを自動認識し 適切な型で出力 | 文字列 | |
| 注意点 | CSVファイルの1行目からデータが始まる 場合は、HDR=NOで1行目から データとして取得が必要 | 処理無しの場合は全て文字列で出力される為、表示時に処理要 | |
7.最後に
既にCSVファイルが決まっている場合には、それに対応できる方法で解析ソフトを考えるしかありません。しかしこれから設備を導入する場合、CSVを吐き出す機能を検討しているのであれば、解析側のことも考えてより加工し易いCSVを考えて頂きたいと思います。
 CSVファイルの読み込み(it-028.xlsm)CSVサンプルファイル(it-csv-01.csv)
CSVファイルの読み込み(it-028.xlsm)CSVサンプルファイル(it-csv-01.csv)|
セキュリティ向上を目的として「インターネット経由でダウンロードしたOfficeファイル(Excel等)のマクロは、既定でブロック」されるようにOfficeアプリケーションの既定動作が変更になりました。(2022年4月より切替開始) 解除の方法については「ダウンロードファイルのブロック解除方法」を参照下さい。 |