可変長配列(Dictionary等)を使った重複除外リスト(複数列)

連想配列などと呼ばれる可変長配列について、下記のようなシリーズで説明しています。
・可変長配列の機能整理
・可変長配列を使った重複除外リスト(単列)
・可変長配列を使った重複除外リスト(複数列) ←今回
今回は「重複しない複数列のリスト」を、「Collection」「Dictionary」「ArrayList」「SortedList」オブジェクトを使って実現させます。また比較のために「For~Next」を使って「同じ値は除外」する方法も併せて載せます。
なお、データ追加時・出力時に様々なアルゴリズムを使って並び変えを行う事は可能ですが、今回は省略しています。但しオブジェクト内に並べ替えのメソッドを持ち、使える場合には使用する事とします。
今回扱うリストは「複数列(二次元配列)」ですが、単列(一次元配列)の場合については別項「可変長配列を使った重複除外リスト(単列)」を参照下さい。但し「添付Excelファイル」は、比較の為に単列・複数列を1つにまとめました。コードは別々(単列はModule1+UserForm1、複数列はModule2+UserForm2)に記述していますが、元データはSheet1で共通です。
1.概要
今回は「ある二次元配列のデータ」をCollectionなどの可変長配列を使って「重複データを除外」し、その結果を確認することで、「各可変長配列の特徴」を把握することを目的としています。そのため図1のように、ワークシート上の元データ(セル値)に「行位置」を仮想データとして加えたものを「二次元配列」とし、その二次元配列をフォーム上のボタンにより重複除外処理を行い、結果をリストボックスに表示することとしました。
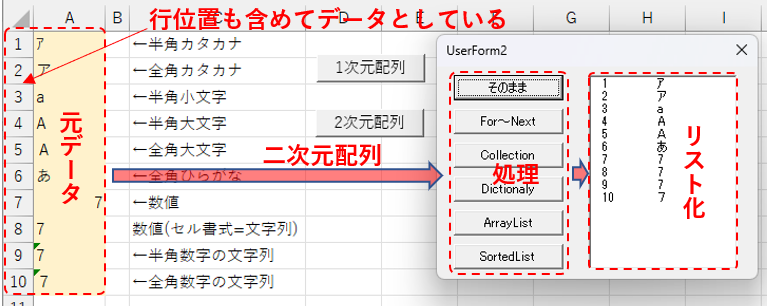
図1
処理コードは以降で1つずつ紹介していきますが、処理の結果は図2のようになりました。

図2
「SortedList」は自動的に並べ替えが行われていますが、単列ではSortメソッドを使って並べ替えが出来ていた「ArrayList」は、内部の値が配列になってしまった為に並べ替えが出来ず、行位置の順に並んでいます。
重複処理の結果は「重複除外処理のまとめ」で整理しますが、「そのまま」は除き全部で3種類の重複判断が存在することが分かりました。
2.マクロ
2-1.ワークシート(Sheet1)
元データは図3のように、Sheet1のA1セルから縦方向に並んでいるものとします。そのデータをフォーム起動時に吸い上げて配列を作成するのですが、その時「行位置」も組み合わせた「二次元配列」を作ります。フォームの起動は、シート上のボタン(今回説明するのは「2次元配列」のボタンの方です)から行います。
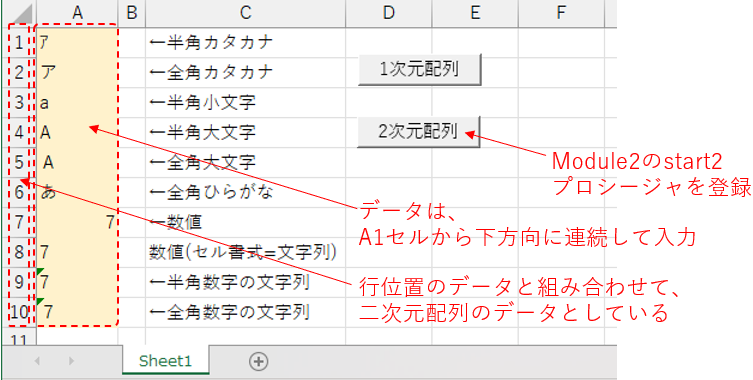
図3
2-2.標準モジュール(Module2)
複数列(二次元配列)のコードは、Module2に記述しています。まず、元データ+行位置(以降では、この組み合わせを元データとします)の二次元配列を「OrgArray2」としてPublic宣言します(図4)。
- '========== ⇩(1) 共通変数の宣言 ============
- Public OrgArray2 As Variant '←ワークシート上の元データ+行位置を二次元配列にしたもの
14 シート上の「2次元配列」のボタンから呼び出されるのが図5です。
12行目「Call DataIn2」では、図6を呼び出して「元データを二次元配列に変換」しています。
13行目「UserForm2.Show 0」では、UserForm2を起動します。ここではモードレス(フォーム起動時にシートの操作が可能)で起動していますが、これはUserForm1とUserForm2を同時起動させて、「一次元配列の処理」と「二次元配列の処理」の比較をできるようにするためです。
- '========== ⇩(2) フォームの起動 ============
- Public Sub start1()
- Call DataIn2
- UserForm2.Show 0
- End Sub
図5の12行目から呼び出されるのが図6です。
- '========== ⇩(3) 元データの配列化 ============
- Private Sub DataIn2()
- Dim r As Range '←元データの先頭セル範囲
- Dim buf As Variant '←仮の戻り値配列
- Dim i As Long '←元データの個数
- Set r = Sheets("Sheet1").Range("A1")
- If r.Value = "" Then
- OrgArray2 = Empty '←データが無い時はEmpty
- Exit Sub
- End If
- buf = r.CurrentRegion
- If IsArray(buf) = False Then
- ReDim buf(1 To 1, 1 To 1)
- buf(1, 1) = r.Value
- End If
- ReDim Preserve buf(1 To UBound(buf, 1), 1 To 2)
- For i = 1 To UBound(buf, 1)
- buf(i, 2) = buf(i, 1)
- buf(i, 1) = i
- Next i
- OrgArray2 = buf
- End Sub
26行目「Set r = Sheets("Sheet1").Range("A1")」では、Sheet1のA1セルを「データ先頭セル」として設定します。
27行目「If r.Value = "" Then」では、先頭セルが空白セルか否かを調べ、空白セルだった場合には「元データは無し」とするため、28行目「OrgArray2 = Empty」で変数OrgArray2にEmptyを設定した上で、29行目「Exit Sub」でプロシージャを抜け出します。
「わざわざEmptyを設定しなくても、OrgArray2はVariant型だから、初期値のEmptyになるのでは」と思われると思います。確かにA1セルにデータが無い時の初回はEmptyになるのですが、違和感が出る場合があります。それは、A1セル以降にデータが並んでいる状態でフォームを開いた後、一旦フォームを閉じてからA1セルのデータを削除する場合です。
この場合、次にフォームを開いた時に「A1セルにデータが無いので、そのままプロシージャを抜け出してしまう」と、変数OrgArray2はEmptyにはならず、1つ前の「A1セル以降にデータがある」状態のままとなってしまうのです。
そのため、28行目で「プロシージャを抜け出す前に、変数OrgArray2にEmptyを設定」しています。
先頭セル(r)に値が入っている場合は、32行目以降で仮の変数bufに元データを格納していきます。
32行目「buf = r.CurrentRegion」は、元データ領域を「先頭セルからつながっている範囲」とするためにCurrentRegionプロパティを使用して取得します。今回のデータは「縦に並んでいる」ために、配列bufも「縦に並んだ二次元配列」となります。
しかしデータが1つ(=A1セルにのみデータがある)の場合には、変数bufは配列にはならず、通常の変数になってしまいます。
ですので、34行目「If IsArray(buf) = False Then」で、変数bufが配列か否かを確認し、配列では無い(=False)場合は、35行目「ReDim buf(1 To 1, 1 To 1)」で変数bufを「二次元配列」にします。Redimで再配列化すると29行目で代入した先頭セルの値はクリアされてしまいますので、36行目「buf(1, 1) = r.Value」で配列要素内に先頭セル値を再度格納します。
ここまでで配列bufは「縦方向(行方向)はデータ数」×「横方向(列方向)は1」の二次元配列です。
この二次元配列を39行目「ReDim Preserve buf(1 To UBound(buf, 1), 1 To 2)」で、配列のサイズを横方向(列方向)に拡大します。Preserveキーワードを付けていますので、入っているデータは「配列bufの1列目」に入ったままです。
41行目「For i = 1 To UBound(buf, 1)」では、カウンタ変数iを配列bufの行数分だけ回します。
42行目「buf(i, 2) = buf(i, 1)」で、1列目のデータ(シート上の元データの値)を2列目にコピーします。
43行目「buf(i, 1) = i」で、1列目に「行位置(カウンタ変数iの値)」を上書きします。
以上を図で説明すると、図7のような流れになります。
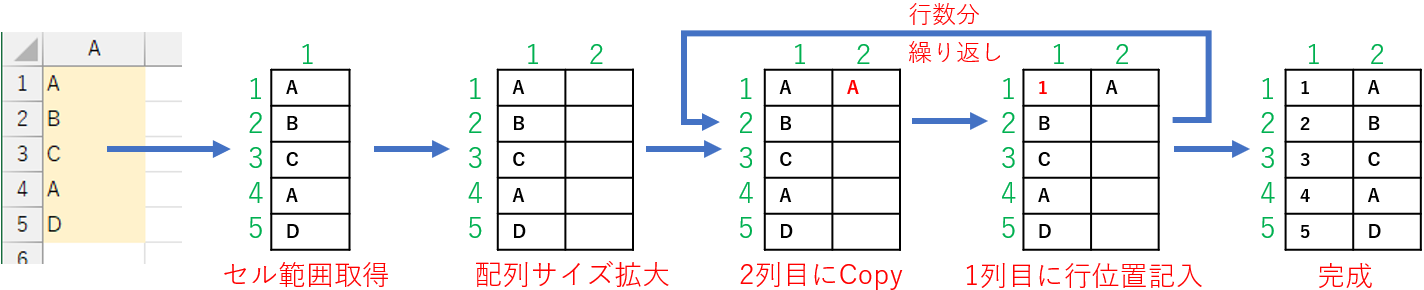
図7
最後に46行目「OrgArray2 = buf」で、「二次元配列OrgArray2」が作成されます。
2-3.ユーザーフォーム(UserForm2)
複数列(二次元配列)のコードは、UserForm2に記述しています。2-3-1.フォームレイアウト
フォーム上のコントロール類のレイアウトは、図8のようにしました。処理を実行するためのボタンを6つと、処理後のデータを表示するためのリストボックスを適当に配置しています。ボタン表面のCaptionは配置時にプロパティ変更しています。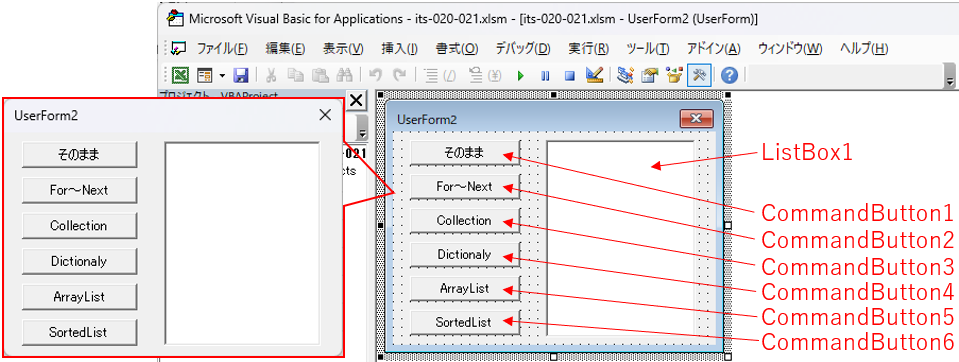
図8
2-3-2.フォームモジュール
2-3-2-1.フォームの初期設定
フォーム起動時のActivateイベント内で、リストボックスを複数列にする設定を行います(図9)。- '========== ⇩(4) フォームの初期設定 ============
- Private Sub UserForm_Activate()
- Me.ListBox1.ColumnCount = 2
- Me.ListBox1.ColumnWidths = "40;40"
- End Sub
52行目「Me.ListBox1.ColumnCount = 2」で、重複除外処理結果を表示するリストボックスを、2列表示にします。
53行目「Me.ListBox1.ColumnWidths = "40;40"」で、各列幅を40ポイントにします。ListBox自体の幅(Width)が100ポイント以上でしたので、横スクロールバーが出ない配分にしています(詳細は「横スクロールバーを出さないリスト」を参照下さい)。
2-3-2-2.ボタンクリックによる分岐
フォーム上のコマンドボタンをクリックした時に呼び出されるのが、図10の各プロシージャです。各プロシージャから呼び出すのはリストボックスのリスト作成をするmakeListプロシージャ(図11)です。makeListプロシージャには、引数として「リスト表示させるための二次元配列」を渡しますが、その二次元配列は「各可変長配列で重複データを除外した配列」となります。
- '========== ⇩(5) ボタンクリックによる分岐 ============
- Private Sub CommandButton1_Click() '←「そのまま」ボタン
- Call makeList(OrgArray2)
- End Sub
- Private Sub CommandButton2_Click() '←「For~Nex」ボタン
- Call makeList(ForNext(OrgArray2))
- End Sub
- Private Sub CommandButton3_Click() '←「Collection」ボタン
- Call makeList(Collect(OrgArray2))
- End Sub
- Private Sub CommandButton4_Click() '←「Dictionary」ボタン
- Call makeList(Dict(OrgArray2))
- End Sub
- Private Sub CommandButton5_Click() '←「ArrayList」ボタン
- Call makeList(ArrayL(OrgArray2))
- End Sub
- Private Sub CommandButton6_Click() '←「SortedList」ボタン
- Call makeList(SortL(OrgArray2))
- End Sub
「そのまま」ボタンをクリックした場合には、図6で作成したオリジナルの「元データ」の配列(OrgArray2)をmakeListに渡してリストを作成します。
「For~Nex」ボタン時には、元データを図12のForNextプロシージャに渡し、重複データを除外した後の二次元配列をmakeListに渡してリストを作成します。
「Collection」ボタン時には、元データを図14のCollectプロシージャに渡し、重複データを除外した後の二次元配列をmakeListに渡してリストを作成します。
「Dictionary」ボタン時には、元データを図15のDictプロシージャに渡し、重複データを除外した後の二次元配列をmakeListに渡してリストを作成します。
「ArrayList」ボタン時には、元データを図19のArrayLプロシージャに渡し、重複データを除外した後の二次元配列をmakeListに渡してリストを作成します。
「SortedList」ボタン時には、元データを図20のSortLプロシージャに渡し、重複データを除外+並べ替えをした後の二次元配列をmakeListに渡してリストを作成します。
2-3-2-3.リストボックス作成
図10の各プロシージャから呼び出され、リストボックスのリストを作成するのが図11です。引数として「リスト化するための二次元配列」を受け取ります。(一次元配列のUserForm1側と全く一緒のコードです)- '========== ⇩(6) リストボックス作成 ============
- Private Sub makeList(ListArray As Variant)
- Me.ListBox1.Clear
- If IsEmpty(ListArray) = True Then Exit Sub
- Me.ListBox1.List = ListArray
- End Sub
93行目「Me.ListBox1.Clear」では、リストを一旦クリアしています。
94行目「If IsEmpty(ListArray) = True Then Exit Sub」では、受け取った引数がEmpty(=1つもデータが無い)だった時には、リスト作成を行わずに終了します。
95行目「Me.ListBox1.List = ListArray」では、配列そのものをリストに直接入れて、一発でリストを作成しています。なお、引数で受け取った二次元配列の要素数分だけ繰り返しながら、1つ1つリスト行を作成する方法でもOKです。
2-3-2-4.For~Next処理
図10の66行目から呼び出されるのが図12です。引数として元データの二次元配列を受け取り、重複を除外した配列を戻します。- '========== ⇩(7) For~Next処理 ============
- Private Function ForNext(ListArray As Variant) As Variant
- Dim buf1 As Variant '←新たな配列
- Dim buf2(1 To 1, 1 To 2) As Variant '←元データ配列の先頭部分
- Dim i As Integer '←引数で受け取った配列の要素数
- Dim j As Integer '←新しい配列の要素数(順次増える)
- If IsEmpty(ListArray) = True Then Exit Function
- buf2(1, 1) = ListArray(1, 1)
- buf2(1, 2) = ListArray(1, 2)
- buf1 = WorksheetFunction.Transpose(buf2)
- For i = 2 To UBound(ListArray, 1)
- For j = 1 To UBound(buf1, 2)
- If buf1(2, j) = ListArray(i, 2) Then Exit For
- Next j
- If j > UBound(buf1, 2) Then
- ReDim Preserve buf1(1 To 2, 1 To UBound(buf1, 2) + 1)
- buf1(1, UBound(buf1, 2)) = ListArray(i, 1)
- buf1(2, UBound(buf1, 2)) = ListArray(i, 2)
- End If
- Next i
- If UBound(buf1, 2) = 1 Then
- ForNext = buf2
- Else
- ForNext = WorksheetFunction.Transpose(buf1)
- End If
- End Function
107行目「If IsEmpty(ListArray) = True Then Exit Function」では、引数がEmpty(=元データが1つも無い)の時に、図12を抜け出します。Functionのデータ型Variantの初期値である「Empty」が呼び出し元に戻る事になります。
データが1つ以上の時の処理は、図13のような流れとしました。

図13
今回は、入力も出力も必ず「二次元配列(値が無ければEmpty)」となるようなプログラムにしています。
そのため、元データを重複除外しながら別な二次元配列にサイズを変えながら入れ直しをすると、配列の最終次元(この場合、列方向)しか変更できないため「配列の行列を逆転」させておく必要があります。配列が完了したらTranspose関数で行列を元の状態に戻せば良いのですが、「データが1行のみ」の場合にTranspose関数を使用すると「二次元配列 → 一次元配列」になってしまいます。
そこで、重複データを除外したとしても「先頭データだけは必ず残る」ことから、先頭データをまず二次元配列として保存しておき、処理の最後に「重複除外したデータが1つのみ」だった場合には、保存しておいたデータ(二次元配列)を採用する という方法です。
109行目「buf2(1, 1) = ListArray(1, 1)」と110行目「buf2(1, 2) = ListArray(1, 2)」では、引数で受け取った配列ListArrayの先頭データを配列buf2に代入します。この配列buf2が、「データが1つのみ」だった場合、及び複数データだったとしても「重複を除外したら1つになった」場合の戻り値となります。
112行目「buf1 = WorksheetFunction.Transpose(buf2)」では、109~110行目で先頭データを代入した配列buf2を行列逆転させ、配列buf1としています(図13の左から3つ目の状態)。Transpose関数を使用していますが「1行×2列 → 2行×1列」にしていますので1次元配列にはならず二次元配列のままです。この配列buf1の「列方向を増やし」ながら、2個目以降のデータを入れていきます。
114行目「For i = 2 To UBound(ListArray, 1)」では、引数として受け取った二次元配列の2行目の要素から最終要素までを回しています。もしListArrayが1つだけのデータ配列だった場合は、Ubound(ListArray, 1) = 1 ですので「For i=2 To 1」となり、For内を実行せずに126行目に移ります。
115行目「For j = 1 To UBound(buf1, 2)」で、新たに作った配列(buf1)の要素数分だけカウンタ変数jを回します。
116行目「If buf1(2, j) = ListArray(i, 2) Then Exit For」では、格納しようとしている値(元データの2列目の値)が既に存在(=重複)したら、115~117行目のFor~Nextを抜け出します。
116行目のIf文が成立して、For~Nextを抜け出す(Exit For)時には、その時点でのカウンタ変数j値がメモリ上に残ります。またIf文が一回も成立せずにFor~Nextが回り切ってしまった場合には、カウンタ変数j値は「UBound(buf1, 2) + 1」になります。これはFor~Nextを回すたびにj値が増え、最後に115行目のFor文で「最終値(UBound(buf1, 2))を超えているからFor~Nextは終了」という判断をするためです。
このj値を使って、重複の有無を119行目「If j > UBound(buf1, 2) Then」で行い、For~Nextが回り切った(=重複は無かった)時に120~122行目を実行します。
120行目「ReDim Preserve buf1(1 To 2, 1 To UBound(buf1, 2) + 1)」で、格納する配列(buf1)のサイズを現在よりも1つ大きなサイズに変更します。既に格納済みのデータを消さないようにPreserveキーワードを付けます。
121行目「buf1(1, UBound(buf1, 2)) = ListArray(i, 1)」と122行目「buf1(2, UBound(buf1, 2)) = ListArray(i, 2)」で、サイズを大きくした配列buf1の一番最後の要素に新しい値を追加します。
114~124行目のFor~Nextを回し、引数で得た元データ配列を重複を除外しながら新たな配列(buf1)に格納し直したら、126行目「If UBound(buf1, 2) = 1 Then」で「データが何個入ったか」を確認します。
個数が1個の場合は127行目「ForNext = buf2」で、109~110行目で作成した「先頭データ配列(buf2)」を関数プロシージャの戻り値に設定します。
一方、個数が1個を超えた(先頭データ以外にもデータが配列に入った)場合は、129行目「ForNext = WorksheetFunction
この場合は、行・列とも複数の配列ですので、Transpose関数で変換しても「二次元配列のまま」となります。
2-3-2-5.Collection処理
図10の70行目から呼び出されるのが図14です。引数として元データの二次元配列を受け取り、重複を除外した配列を戻します。- '========== ⇩(8) Collection処理 ============
- Private Function Collect(ListArray As Variant) As Variant
- Dim C As Collection '←Collectionオブジェクトの宣言
- Dim buf() As Variant '←新たな配列
- Dim i As Integer '←引数で受け取った配列の行数
- If IsEmpty(ListArray) = True Then Exit Function
- Set C = New Collection
- For i = 1 To UBound(ListArray, 1)
- On Error Resume Next
- C.Add Item:=Array(ListArray(i, 1), ListArray(i, 2)), Key:=CStr(ListArray(i, 2))
- On Error GoTo 0
- Next i
- ReDim buf(1 To C.Count, 1 To 2)
- For i = 1 To UBound(buf, 1)
- buf(i, 1) = C.Item(i)(0)
- buf(i, 2) = C.Item(i)(1)
- Next i
- Collect = buf
- Set C = Nothing
- End Function
146行目「If IsEmpty(ListArray) = True Then Exit Function」では、引数がEmpty(=元データが1つも無い)の時に図14を抜け出し、Variant型の初期値であるEmptyを戻します。
148行目「Set C = New Collection」では、Collectionオブジェクトを生成します。
150~154行目では、Collectionオブジェクトに元データを1つずつ追加していきます。Collectionの「KeyはString型で指定」する必要があり、またKeyの重複は出来ません。と言って、他可変長配列のように「Keyの存在をチェックするメソッド」がありませんので、ここでは「無理やり追加してみて、エラーが出たら重複していると判断」することにします。
150行目「For i = 1 To UBound(ListArray, 1)」では、カウンタ変数iを元データ配列の要素数分だけ回します。
152行目「C.Add Item:=Array(ListArray(i, 1), ListArray(i, 2)), Key:=CStr(ListArray(i, 2))」では、Keyには「文字列型にした値(元データのセルの値)」を設定し、Itemには「1データ(=2つの値)を配列」の形にして設定します。
Keyに重複が無ければそのまま格納されますが、重複していれば「エラーが発生し、格納はされない」ことになります。エラーが発生するとプログラムが止まってしまいますので、151行目「On Error Resume Next」でエラーはスルーさせます。
Collectionオブジェクトへの格納が終了したら、156~160行目で値を取り出し、別な配列(buf)に格納し直します。
まず156行目「ReDim buf(1 To C.Count, 1 To 2)」で、配列bufのサイズを指定します。Collectionに格納した要素数はC.Countで得られますので、その数と同じ縦サイズの配列にします。横は2列分を確保します。
157行目「For i = 1 To UBound(buf, 1)」では、カウンタ変数iを配列bufの要素数(=Collectionの要素数)分だけ回します。
158行目「buf(i, 1) = C.Item(i)(0)」で、Collectionの値(C.Item(Index) がCollectionに格納されている配列)の内、配列の1つ目の要素の値(インデックスはゼロ)を配列bufの1つ目の要素に代入します。
159行目「buf(i, 2) = C.Item(i)(1)」では、Collectionの値(=配列)の2つ目の要素の値(インデックスは1)を配列bufの2つ目の要素に代入します。
配列bufへの代入が完了したら、162行目「Collect = buf」で関数プロシージャCollectの戻り値に配列bufを設定します。
2-3-2-6.Dictionary処理
図10の74行目から呼び出されるのが図15です。引数として元データの二次元配列を受け取り、重複を除外した配列を戻します。- '========== ⇩(9) Dictionary処理 ============
- Private Function Dict(ListArray As Variant) As Variant
- Dim D As Object '←Dictionaryオブジェクトの宣言
- Dim buf(1 To 1, 1 To 2) As Variant '←元データ配列の先頭部分
- Dim i As Integer '←引数で受け取った配列の行数
- If IsEmpty(ListArray) = True Then Exit Function
- buf(1, 1) = ListArray(1, 1)
- buf(1, 2) = ListArray(1, 2)
- Set D = CreateObject("Scripting.Dictionary")
- For i = 1 To UBound(ListArray, 1)
- If D.Exists(ListArray(i, 2)) = False Then
- D.Add Item:=Array(ListArray(i, 1), ListArray(i, 2)), Key:=ListArray(i, 2)
- End If
- Next i
- If D.Count = 1 Then
- Dict = buf
- Else
- Dict = D.Items
- Dict = WorksheetFunction.Transpose(Dict)
- Dict = WorksheetFunction.Transpose(Dict)
- End If
- Set D = Nothing
- End Function
176行目「If IsEmpty(ListArray) = True Then Exit Function」では、引数がEmpty(=元データが1つも無い)の時に図15を抜け出し、Variant型の初期値であるEmptyを戻します。
このDictionaryで処理する場合も、For~Next(図12)と同じく193~194行目でTranspose関数を使用するため、先頭データを事前に保存しておく必要があります。
178行目「buf(1, 1) = ListArray(1, 1)」と179行目「buf(1, 2) = ListArray(1, 2)」では、引数で受け取った配列ListArrayの先頭データを配列bufに代入します。この配列bufが、「データが1つのみ」だった場合、及び複数データだったとしても「重複を除外したら1つになった」場合の戻り値となります。
181行目「Set D = CreateObject("Scripting.Dictionary")」では、Dictionaryオブジェクトを生成します。
183~187行目では、Dictionaryオブジェクトに元データを1つずつ追加していきます。
183行目「For i = 1 To UBound(ListArray, 1)」では、カウンタ変数iを元データ配列の要素数分だけ回します。
Dictionaryオブジェクトには「Keyの存在を調べるExistsメソッド」がありますので、184行目「If D.Exists(ListArray(i, 2)) = False Then」でKeyの重複調査をします。調べる値は、元データの2列目(セルの値)です。
そのKeyの調査結果がFalse(=重複が無い)の時に、185行目「D.Add Item:=Array(ListArray(i, 1), ListArray(i, 2)), Key:=ListArray(i, 2)」でDictionaryオブジェクトにデータを追加します。Keyには元データの2列目のセル値を、Itemには元データの値のセットを配列の形にして設定します。
なおDictionaryオブジェクトにデータを追加する手段として「Dictionary.Item(Key) = Item」という方法もあります。これは「データの修正」にも使用できるため、Existsメソッドを使用せずに「重複が有ったら上書き」していく、という事にも使えます。この方法を使用すると、図15の183~187行目を図16のように置き換える事ができます。
- For i = 1 To UBound(ListArray, 1)
' If D.Exists(ListArray(i, 2)) = False Then- D.Item(ListArray(i, 2)) = Array(ListArray(i, 1), ListArray(i, 2))
' End If- Next i
Dictionaryオブジェクトへのデータ追加が完了したら、For~Nextの時と同様に「重複を除外したデータ行が1行か1行超か」で処理を分ける必要があります。
189行目「If D.Count = 1 Then」で、Dictionaryオブジェクトのデータが1つか否かを調べ、1つの時には190行目「Dict = buf」で、178~179行目で作成した「先頭データの配列(buf)」を関数プロシージャの戻り値に設定します。
一方、複数データの場合は192行目「Dict = D.Items」で、まず「全ての値」を変数Dictに代入します。この際、Dictionaryの1つ1つには「一次元配列(2要素)」が格納されていますので、全ての値を取り出した結果は、図17の左から2番目のように「一次元配列が入れ子(ネスト)となった配列」となります。

図17
しかし「入れ子の一次元配列」は「二次元配列」とは異なるため、リストボックスに一気に貼り付ける事はできません。ですので、193~194行目「Dict = WorksheetFunction.Transpose(Dict)」と、Transpose関数を2回使う事で「二次元配列」に変更します。この時、配列のインデックスも「ゼロ始まり → 1始まり」に変わります。
この二次元配列が関数プロシージャの戻り値となります。
なお「Itemsメソッド」を使った「一気に配列化」処理をせず、図18のようにFor~Nextを使って1データずつ代入しても同じ結果が得られます。この方法の時には、データ数が1個の時は考えなくても良いので、178~179行目の「先頭データを作る」必要は無くなります。
- ReDim buf(1 To D.Count, 1 To 2) '←戻す配列サイズを設定
- For i = 1 To UBound(buf, 1) '←Dictionaryのデータ数だけ回す
- buf(i, 1) = D.items()(i - 1)(0) '←1列目を代入
- buf(i, 2) = D.items()(i - 1)(1) '←2列目を代入
- Next i
- Dict = buf '←関数プロシージャの戻り値に設定
2-3-2-7.ArrayList処理
図10の78行目から呼び出されるのが図19です。引数として元データの二次元配列を受け取り、重複を除外した配列を戻します。- '========== ⇩(10) ArrayList処理 ============
- Private Function ArrayL(ListArray As Variant) As Variant
- Dim A1 As Object '←ArrayListオブジェクトの宣言(重複検出用)
- Dim A2 As Object '←ArrayListオブジェクトの宣言(配列保存用)
- Dim buf(1 To 1, 1 To 2) As Variant '←先頭データの配列
- Dim i As Integer '←引数で受け取った配列の行数
- If IsEmpty(ListArray) = True Then Exit Function
- buf(1, 1) = ListArray(1, 1)
- buf(1, 2) = ListArray(1, 2)
- Set A1 = CreateObject("System.Collections.ArrayList")
- Set A2 = CreateObject("System.Collections.ArrayList")
- For i = 1 To UBound(ListArray, 1)
- If A1.Contains(ListArray(i, 2)) = False Then
- A1.Add Value:=ListArray(i, 2)
- A2.Add Value:=Array(ListArray(i, 1), ListArray(i, 2))
- End If
- Next i
- If A2.Count = 1 Then
- ArrayL = buf
- Else
- ArrayL = A2.toArray
- ArrayL = WorksheetFunction.Transpose(ArrayL)
- ArrayL = WorksheetFunction.Transpose(ArrayL)
- End If
- Set A1 = Nothing
- Set A2 = Nothing
- End Function
ArrayListもDictionaryと同様に「一気に取得した値が一次元配列の入れ子のために、最後でTranspose関数を使う」必要があるタイプです。なお図18のようにFor~Nextで1つずつ値を取得すれば、Transposeを使わなくてもOKです。
217行目「If IsEmpty(ListArray) = True Then Exit Function」では、引数がEmpty(=元データが1つも無い)の時に図19を抜け出し、Variant型の初期値であるEmptyを戻します。
219行目「buf(1, 1) = ListArray(1, 1)」と220行目「buf(1, 2) = ListArray(1, 2)」では、引数で受け取った配列ListArrayの先頭データを配列bufに代入します。この配列bufが、「データが1つのみ」だった場合、及び複数データだったとしても「重複を除外したら1つになった」場合の戻り値となります。
222行目「Set A1 = CreateObject("System.Collections.ArrayList")」、223行目「Set A2 = CreateObject("System.Collections.ArrayList")」では、2つのArrayListオブジェクトを生成しています。1つ目「A1」は、重複を検知させるためのデータ(セル値)を入れるArrayListオブジェクト、2つ目「A2」は、セットのデータ(行位置+セル値)を入れるArrayListオブジェクトです。
ArrayListには「Keyが無い」のと、セットの値を格納しても「値が配列だと、重複しているか否かを判断できない」のが、2つオブジェクトを作る理由です(A1をKeyとして、A2を値として使っているイメージ)。
225~230行目では、重複の有無を確認しながらArrayListに値を格納しています。
225行目「For i = 1 To UBound(ListArray, 1)」では、カウンタ変数iを引数で受け取った元データのデータ数だけ回します。
226行目「If A1.Contains(ListArray(i, 2)) = False Then」では、A1オブジェクト(Keyの役目をしている方)の中に、元データの2列目のセル値が有るか否かを調べ、無かった(=重複していない)時に227行目「A1.Add Value:=ListArray(i, 2)」でA1オブジェクトにセル値を格納します。
と同時に228行目「A2.Add Value:=Array(ListArray(i, 1), ListArray(i, 2))」で、元データの「行位置+セル値」のセットを配列の形でA2オブジェクトに格納します。
格納が完了したら、232行目「If A2.Count = 1 Then」でArrayListオブジェクトのデータが1つか否かを調べます。A1オブジェクトとA2オブジェクトは227~228行目で同時に作業をしていますので、A1・A2どちらの数を数えても同じです。
データが1つの時には233行目「ArrayL = buf」で、219~220行目で作成した「先頭データの配列」を関数プロシージャの戻り値に設定します。
一方、複数データの場合は、235行目「ArrayL = A2.toArray」で「全ての値」を変数ArrayLに代入します。この際、配列ArrayLはDictionaryの場合と同様に「一次元配列が入れ子(ネスト)となった配列」となります。
ですので236~237行目「ArrayL = WorksheetFunction.Transpose(ArrayL)」と、Transpose関数を2回使う事で「二次元配列」に変更します。この時、配列のインデックスも「ゼロ始まり → 1始まり」に変わります。
この二次元配列が関数プロシージャの戻り値となります。(図17参照)
なおA1オブジェクトには、元データのセル値を「そのままのデータ型」で格納しています。ArraysListに収める値は、後でSortメソッドで並べ替えを行う場合には「データ型を揃えておかないとエラーが発生」しますが、Sortを使わない時にはデータ型が混在していてもOKです。
今回はA1で仮にSortをしても、セットのデータを収めているA2の方が並べ変わらないために、A1に格納する値はデータ型を揃える(String型)事はしませんでした。そのため、一次元配列の時の並べ替えを行った時とは「重複を除外したリスト」の個数が異なる事にも注目下さい。
また、データを1つ1つ取り出すという図18のような手法を使えば、Transpose関数を使わずに済み「個数が1か1超か」のIf文を使わずに処理ができます。
2-3-2-8.SortedList処理
図10の82行目から呼び出されるのが図20です。引数として元データの二次元配列を受け取り、重複を除外+並べ替えをした配列を戻します。- '========== ⇩(11) SortedList処理 ============
- Private Function SortL(ListArray As Variant) As Variant
- Dim S As Object '←SortedListオブジェクトの宣言
- Dim buf() As Variant '←新たな配列
- Dim i As Integer '←引数で受け取った配列の行数
- If IsEmpty(ListArray) = True Then Exit Function
- Set S = CreateObject("System.Collections.SortedList")
- For i = 1 To UBound(ListArray, 1)
- If S.ContainsKey(CStr(ListArray(i, 2))) = False Then
- S.Add Value:=Array(ListArray(i, 1), ListArray(i, 2)), Key:=CStr(ListArray(i, 2))
- End If
- Next i
- ReDim buf(1 To S.Count, 1 To 2)
- For i = 1 To UBound(buf, 1)
- buf(i, 1) = S.GetByIndex(i - 1)(0)
- buf(i, 2) = S.GetByIndex(i - 1)(1)
- Next i
- SortL = buf
- Set S = Nothing
- End Function
256行目「If IsEmpty(ListArray) = True Then Exit Function」では、引数がEmpty(=元データが1つも無い)の時に図20を抜け出し、Variant型の初期値であるEmptyを戻します。
258行目「Set S = CreateObject("System.Collections.SortedList")」では、SortedListオブジェクトを生成します。
260~264行目では、SortedListオブジェクトに元データを1つずつ追加していきます。
260行目「For i = 1 To UBound(ListArray, 1)」では、カウンタ変数iを元データ配列の要素数分だけ回します。
SortedListオブジェクトには「Keyの存在を調べるContainsKeyメソッド」がありますので、261行目「If S.ContainsKey(CStr(ListArray(i, 2))) = False Then」でKeyの重複調査をします。
その調査結果がFalse(=Keyの重複が無い)の時に、262行目「S.Add Value:=Array(ListArray(i, 1), ListArray(i, 2)), Key:=CStr(ListArray(i, 2))」でArrayListオブジェクトにデータを追加します。なおSortedListオブジェクトのKeyは「データ型の混在はNG」ですので、全て文字列型に揃えるためにCstr関数を使いデータ型変換をします。また値(Value)には、元データの行位置+セル値のセットを配列にして格納します。
なお、SortedListではデータ追加・データ修正の手段に「SortedList.Item(Key) = Value」が使えますので、260~264行目は図21のように置き換えることができます。
- For i = 1 To UBound(ListArray, 1)
' If S.ContainsKey(CStr(ListArray(i, 2))) = False Then- S.Item(CStr(ListArray(i, 2))) = Array(ListArray(i, 1), ListArray(i, 2))
' End If- Next i
格納が完了したら、266~270行目で値を取り出し、別な配列(buf)に格納し直します。
まず266行目「ReDim buf(1 To S.Count, 1 To 2)」で、格納する配列bufのサイズを指定します。
267行目「For i = 1 To UBound(buf, 1)」では、カウンタ変数iを配列bufの要素数(=SortedListの要素数)分だけ回します。
268行目「buf(i, 1) = S.GetByIndex(i - 1)(0)」で、「SortedListの値(=配列)の内、1列目(インデックスはゼロ)の値を配列bufの1列目の要素へ代入します。
269行目「buf(i, 2) = S.GetByIndex(i - 1)(1)」では、2列目(インデックスは1)の値を配列bufの2列目の要素へ代入します。
配列bufへの代入が完了したら、272行目「SortL = buf」で関数プロシージャSortLの戻り値に配列bufを設定します。
3.重複除外処理のまとめ
上記の「For~Next」と4種の可変長配列の処理の結果について整理すると、図22のようになります。処理前の値の形を基準とし、各方法で同一と判断する範囲を緑線で囲っています。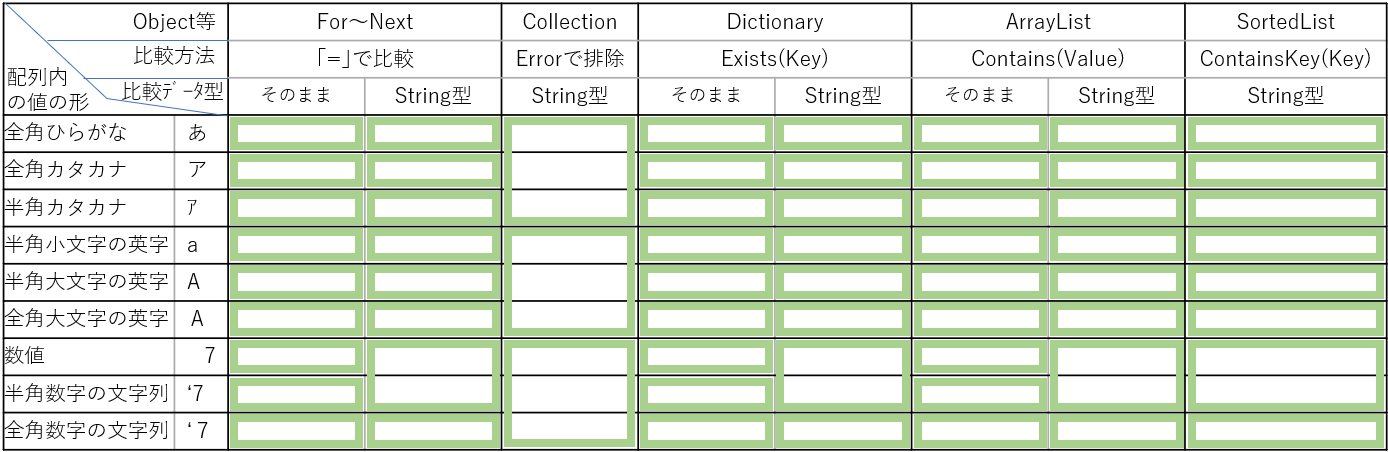
図22
「単列(一次元配列)」の時と同じ表となりましたが、「Collectionオブジェクト」では「大文字小文字・全角半角・ひらがなカタカナ」は同じとして処理し、それ以外では、Keyや値に格納する時に、並べ替えに必要な「データ型の統一」のための文字列変換(String型)を行った時には、当然ながら配列内の「数値」と「文字列にした数字」は同一扱いになります。
ArrayListでは、単列の場合にはSortを行うために「値はCStrで文字列変換」をしましたので「数値と数字の文字列」は一緒とみなされましたが、今回複数列の場合には「Sortを行わないため、そのままのデータ型」としたため別扱いとなっています。もちろん文字列変換をしても良いので、システムに合わせて工夫して下さい。
今回は、各可変長配列の値として「配列」を格納しました。データとして使ったのが2列だったので「Key=セルの値」「値=行位置」という設定にすれば、値を一次元配列として扱える(ArrayList以外)ので、もっと簡単なコードにできると思います。
但し今回、値に配列を無理やりにでも入れる事にこだわったのは、2列のデータでは無く「3列以上のデータ」も考えての事です。3列以上であっても今回と考え方は同じで、格納時と取り出し時に「配列の要素数を増やす」だけで実現できます。
アプリ実例
「CSVファイルでデータを読み書きする月間予定表」「サンプリング周期が異なるデータの補間法」
「複数行1データの並び替え」
「データの重みを考慮したComboBox入力補助」
「先入先出の入出庫管理システム」
「DVD等の内容・保管場所等管理システム」
|
セキュリティ向上を目的として「インターネット経由でダウンロードしたOfficeファイル(Excel等)のマクロは、既定でブロック」されるようにOfficeアプリケーションの既定動作が変更になりました。(2022年4月より切替開始) 解除の方法については「ダウンロードファイルのブロック解除方法」を参照下さい。 |