テキストファイルの読み書き(文字コード編)

VBAを使い「テキストファイルを読み書き」する手法について、以下のようなシリーズで紹介していきます。
①テキストの文字コードについて ←今回
②Openステートメント法による読み書き
③ADODB.Stream法による読み書き
④TextStream法による読み書き
⑤XMLHTTP法によるWebデータの読み取り
⑥Web上からダウンロードして読み取り
今回紹介する「文字コード」は、読み書き手法と直接関係が無いように思えるかもしれません。しかし下表のように「手法により、扱える文字コードが異なる」ので、テキストファイルを作る側では「保存時の文字コード」に注意が必要となります。
(図01に載せている文字コード(横軸)は、Windows付属のメモ帳で保存できる範囲の文字コードに絞っています。)
| 読み書き手法 | Shift-JIS | UTF-8 | UTF-16 | |
|---|---|---|---|---|
| ② | Openステートメント | 〇 | × | △ |
| ③ | ADODB.Stream | 〇 | 〇 | 〇 |
| ④ | TextStream | 〇 | × | 〇 |
| ⑤ | XMLHTTP | (〇) | 〇 | (〇) |
図01
なお上記以外にも、テキストファイルを扱う手法は存在します。
その1つとしてConnection法(ADODB.Connection + ADODB.Recordset)という手法が存在しますが、これはCSVファイルをデータベースのテーブルとして扱う手法ですので、今回は割愛しています。Connection法については「CSVファイルの読み込み」で少し説明していますので参考にして下さい。
1.テキストファイルの概要
PCが扱うファイルは、「テキストファイル」と「バイナリファイル」に分けられると言われます。しかしその実体は、どちらも1と0の集まりである事に変わりはありません。その中でテキストファイルが特別に分類されている理由は、文字コード(文字毎に割り当てられた1と0の並べ方)が世界共通で決められており、且つメモ帳などの「簡単なアプリ」で読み書きできる文字に変換できるためです。
しかしそれ以上に、文字コードは1文字当たり1~数バイトという小さな単位なので、1・0の集まりを文字コード表と見比べることで「人間の目でも何とか判別」する事が可能です。一方で画像ファイルにも1・0を並べる規則はもちろんありますが、そのコードを読み取り描かれている絵を思い浮かべられる人はほとんど居ないと思います。
私はこのあたりから一般ファイルよりも身近なものとして、また親しみを込めて「テキストファイル」と呼んでいるのではないかと感じます。
1-1.テキストの拡張子
Excelでは、テキストファイルを開いたり、テキストファイルとして保存したりできます。下図のように拡張子としては「*.prn」「*.txt」「*.csv」の3つが標準として扱われているようです。
図02
各拡張子の内容は以下のようになります。
| *.prn | 「スペース区切り」でデータを分割したテキストファイル。データベースのテーブルにも使用可。 |
| *.csv | 「カンマ区切り」でデータを分割したテキストファイル。データベースのテーブルとして用いられる事が多い。 |
| *.txt | データベースのテーブルでは無く、データは一般の「文章」が多い。Windowsメモ帳では既定の拡張子。 |
またテキストファイルであれば、拡張子に関わらず内容は同じです。例えば「*.txt」拡張子のファイルに、カンマ区切りのテーブルデータを書き込んでもOKです。しかし利用側には分かり難くなるので、中身に合った拡張子を選ぶのが大切と思います。
1-2.テキストの種類
同じテキストファイルの処理でも、「文字コード」によって読み込む手法が異なってきます。例えばWindows付属のメモ帳でファイル保存する際には、以下の様に5種類の文字コード(エンコード)が選択可能です。
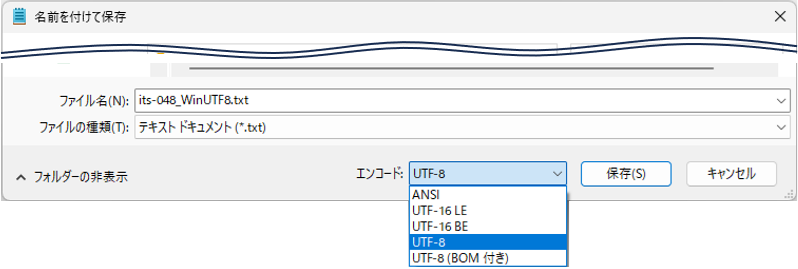
図03
実際には、この他にも数多くの種類が存在しますが、世の流れとしては「UTF-8(メモ帳の既定の文字コード)」が主流になりつつあるようです。今回は、メモ帳で選択できる文字コード+α に絞って説明していきます。
なお、メモ帳で指定できる文字コードをもう少し詳しく説明すると以下のようになります(Window10以降)。
| メモ帳の表示 | 内容 | ||
|---|---|---|---|
| 文字コード | バイト順 | BOM有無 | |
| ANSI | Shift-JIS | (BE) | 無し |
| UTF-16LE | UTF-16 | LE | 付き |
| UTF-16BE | UTF-16 | BE | 付き |
| UTF-8 | UTF-8 | BE | 無し |
| UTF-8(BOM付き) | UTF-8 | BE | 付き |
なお表内の「ANSI」は、American National Standards Institute の略で、日本で言えばJISみたいな機関です。メモ帳上のANSIは「使用される各国の標準言語コード」みたいな意味らしく、日本ではShift-JISとなります。
また上表の、LE(Little-Endian)/BE(Big-Endian)、BOM(Byte Order Mark)については、「バイトの順序」で説明します。
2.文字コードについて
一般的に使われている「文字コード」には2つの意味があります。1つ目は「ある文字をどの番号(コード)に割り振るか」で、正式には「符号化文字集合(Coded Character Set:略CCS )」と呼びます。別な呼び方として、キャラクタセット、文字セット 等があるようです。
2つ目は「文字のコードを、どのようなルールでバイト列に配置するか」で、正式には「文字符号化方式(Character Encoding Scheme:略CES )」と呼びます。別な呼び方としては、文字符号化形式、エンコード 等があるようです。
Excelやメモ帳で開いたり保存したりする際には、バイトの並び方とコードを対応付けていく必要があるので、2つ目の意味合いとなります。
以下で、この2つの意味を明確に分けて説明していく自信はありません。しかし実際にはファイル上に並んだバイト値と順序が重要なので、Shift-JIS・UTF-8・UTF-16LEなどの文字符号化方式の方をまず意識し、それぞれの文字コード間のつながりを確認する時に符号化文字集合を考えれば良いのではないかと思います。
2-1.文字コードの種類
メモ帳で選択できる「ANSI(Shift-JIS)」「UTF-8」「UTF-16」について、上記の2つの意味を下表で整理しました。| 符号化文字集合 | 文字符号化方式 | ||||||
|---|---|---|---|---|---|---|---|
| 文字コード | コード桁数 | 方式 | サイズ/文字 | 特徴 | バイト順 | BOM | |
| ANK (≒ASCII+半角カナ) | 1バイト | Shift-JIS | 1~2バイト | ANKコードはそのまま1バイトとし、 ANKの未使用部(1バイト目) x 2バイト目のコード を組み合わせて日本語コードを割り当て | (BE) | 無 | |
| JIS x 0208 (漢字、ひらがな等) | 2バイト | ||||||
| Unicode (全世界の文字を統一) | Max 21ビット | UTF-8 | 1~4バイト | コードによりバイトサイズを可変長。 1バイト文字はASCIIと互換性有り (半角カナは3バイト文字) | BE | 有/無 | |
| UTF-16 | 2バイト 又は4バイト | 2バイトで収まるコードは2バイト 2バイト超のコードは4バイト | LE/BE | 有/無 | |||
| UTF-32 | 4バイト | コードをそのまま4バイトの固定長で表現 | LE/BE | 有/無 | |||
「Shift-JIS」は、ANKとJIS x 0208という2つの文字コードを表示する方式です。
ANKは「アルファベット+数字(≒ASCII)」と「半角カナ」を 16 × 16 のコードで表すもので、Shift-JISとしてもそのまま1バイト文字として使用します。
そのANKのコードは 16 × 16(=1バイト)の全てを埋め尽くしている訳では無く、使用されていない部分が約25%あります。Shift-JISでは、その1バイト目の残りの部分と2バイト目を組み合わせて、日本語(ひらがな、カタカナ、漢字など)のコードを割り当てています。ですので日本語の文字は2バイト文字となります。
「Unicode」は、全世界の文字を統一的に扱える単一文字コードとして作られ、100万超のコード(21ビット分)に各国の文字が割り当てられています(75%は未使用だそうです)。この21ビットのUnicodeを実際に表示する方法として「UTF-8」「UTF-16」「UTF-32」の3種類があります。
今後の主流と考えられているのが「UTF-8」です。ASCIIコード(アルファベット+数字 =7ビット)の分は、UTF-8ではそのまま1バイト文字に割り当てられます。7ビットを超えたコードは2~4バイト文字となります。
少し分かり難いので、Unicodeのコード番号範囲と各ビットをバイト単位に振り分ける方法を表にしておきます。
| 文字コード範囲 | ビット単位 | 1バイト目 | 2バイト目 | 3バイト目 | 4バイト目 |
|---|---|---|---|---|---|
| U+000000~U+00007F | 0000 0000 0000 0000 0gfe dcba | 0gfe dcba | - | - | - |
| U+000080~U+0007FF | 0000 0000 0000 0kji hgfe dcba | 110k jihg | 10fe dcba | - | - |
| U+000800~U+00FFFF | 0000 0000 rqpn mkji hgfe dcba | 1110 rqpn | 10mk jihg | 10fe dcba | - |
| U+010000~U+1FFFFF | 000w vuts rqpn mkji hgfe dcba | 1111 0wvu | 10ts rqpn | 10mk jihg | 10fe dcba |
「UTF-16」は、Unicodeの2バイトで収まるコードについては2バイトで、それを超えるコードは4バイトで表示します。
「UTF-32」はUnicodeの21ビットをそのまま固定の4バイトに格納する方法です。
 (UTF-32について) (UTF-32について)なお、Unicodeの方式には「UTF-8、-16、-32」の3種がありますので、図05の表の一番下にUTF-32についても記載しました。このUTF-32のテキストファイルは、Windowsのメモ帳では作成や読み込みが出来ませんが、他のエディタ等を使えば可能です。 しかしこのUTF-32をVBAで読み込もうとすると、うまく読み込めません。例えばADODB.Streamオブジェクトを使う場合にCharsetプロパティに指定する「文字コードを示す文字列」は"UTF-32" ではエラーが発生してしまいます。他にも色々試してみましたが辿り着きません。 方法としては、"UTF-16"で読み込んだ後で「1文字置きに文字を取り出す(≒文字間の0x00 0x00 を削除)」ような細工を行えば、なんとか正常な文章が取り出せそうですが、残念ながらUnicodeでは「日本語は3バイト目もコードを使用」しているようなので、単純なアルゴリズムでは太刀打ちできません。 以上からVBAで読み取り等を行う際は「メモ帳で変換できる範囲の文字コード」に抑えておいた方が良いのかもしれません。 |
2-2.バイトの順序
「複数のバイトのコード」を並べる際には、並べるバイト順を決める必要があります。つまり、上位バイトから並べる(BE:Big-Endian )か下位バイトから並べる(LE:Little-Endian )かの2種です。その並び順(LE/BE)を区別し易いようにするのがBOM(Byte Order Mark)です。ファイル先頭に置かれた特定のバイトの順番を見ることで、そのファイルがLEかBEかを判別できるようにするものです。
|
(バイトの並び順とBOM) 例えば半角の「A」という文字は、Unicodeのコード番号では「U+0041」となります(Unicodeの場合は、先頭に「U+」を付けるルールになっている)。この「0x0041」という16ビット(=2バイト)は、上位バイトが「0x00」下位バイトが「0x41」となります。 この複数バイトを「上位バイト → 下位バイト」の順序で並べるのがBE(Big-Endian)で、「下位バイト → 上位バイト」の順序で並べるのがLE(Little-Endian)です。 例えば、図07の左列(BOM無し側)のUTF-16LEとUTF-16BEの先頭文字「A」を見比べてみます。上記のように半角「A」は「0x0041」ですので、LEでは「下位41 → 上位00」の順になり、BEでは「上位00 → 下位41」の順になっています。 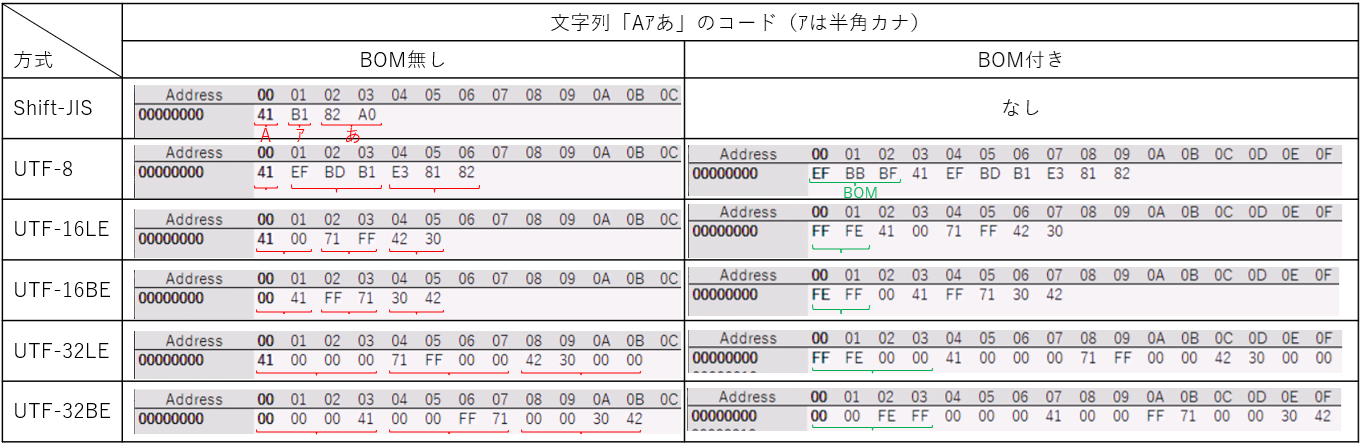 図07 しかし、ファイルが「LE」「BE」のどちらであるかが明確である場合は問題ありませんが、それが不明な状態のまま読み込みを行おうとする時は「LE、BEのどちらだろう?」と各バイト値と文字コードを見比べながら判断しなければならなくなります。 この判断を確実に行うため「読み込もうとしているファイルがLE、BEのどちらなのか」を知る手がかりがBOM(Byte Order Mark)で、ファイルの先頭に決まったコード(U+FEFF)が置かれます。このUnicodeのコードも2バイトですので、UTF-8,16,32それぞれの「バイト配置ルール」と「バイト並び順」に従ってバイト配置されます。例えば、BE(Big-Endian)でのBOMは以下の様になります。 UTF-8 :0xEF 0xBB 0xBF UTF-16:0xFE 0xFF UTF-32:0x00 0x00 0xFE 0xFF (UTF-8だけ異なるコードに見えますが、U+FEFFを図06のルールでバイト配置すると「0xEF 0xBB 0xBF」となります) これを実際に確かめるために、Windowsのメモ帳やサクラエディタで様々な文字コード+BOM有無のテキストファイルを作り、バイナリエディタ(今回はFavBinEditを使用)で確認してみた結果が図07です。 図07の右列が「BOM付き」で、緑色のカッコで示した部分が「BOM」になります。この先頭情報を解析することで、そのファイルのLE・BEの区別ができます。 |
2-3.文字コードの歴史
最後に、文字コードの歴史を大雑把に紹介します。この歴史は、図01で紹介したように「テキストを読み書きする各手法がどの文字コードに対応しているか」に影響しているように思われます。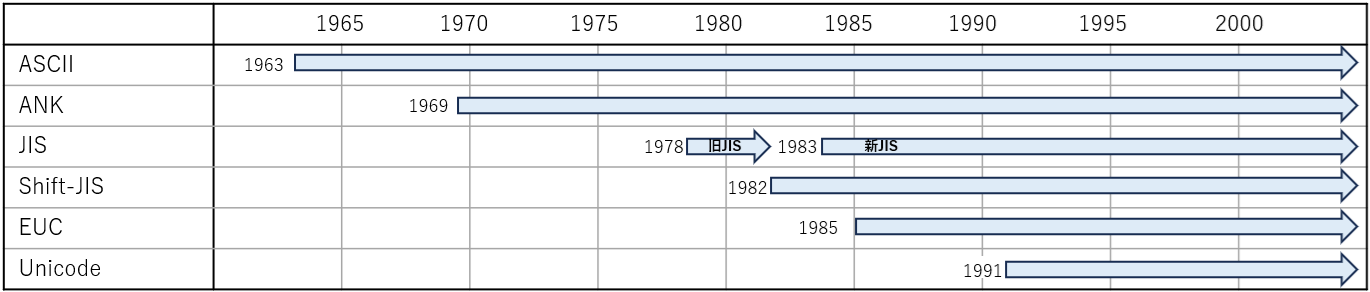
図08
もっとも古いのは、もちろんASCIIコードです。ASCIIは「アルファベット+数字+制御文字」で7ビットで収まります。
しかしASCIIだけでは、日本ではローマ字しか使えず不便です。そこで1バイト内でASCIIが使っていない部分に半角カナ文字を割り当てたのがANKコードです(多少ASCII部分も変えています)。
1978年ごろからはJISコードが表れ、漢字が使えるようになりました。また1982年にはMicrosoft社等で作られたShift-JISコードが誕生します。
その後1985年にはUNIXで各国語を使えるようにEUCコードが誕生し、1991年にはUnicodeが生まれます。
現在、日本語Windowsでは最も新しいUnicodeのUTF-8が主流になりつつありますが、一旦生まれた他の文字コードがそう簡単に消える訳は無く、今後も並走していくはずです。ですので各文字コードの知識は知っておいて損は無いと思います。
アプリ実例・関連する項目
「計算や検索を行うサイトからデータを取得する」「CSVファイルの読み込み」
「OLEObjectのラベルカレンダー(同一ブック内)」
「DVD等の内容・保管場所等管理システム」
「ListObjectの絞り込み」
「ListObjectの並べ替え」
「CSVファイルでデータを読み書きする月間予定表」