データを操作するSQL文

- 1.データの抽出(Select)
- 1-1.列内の値を検索
- 1-1-1.全ての列のデータを抽出
- 1-1-2.特定の列のデータを抽出
- 1-1-3.抽出されたデータの加工
- 1-1-4.ヌル値の扱い(Is Null)
- 1-2.複数の条件式(And、Or)
- 1-3.複数の値と合致するデータの抽出(In)
- 2.並べ替え(Order by)
- 3.集合関数とグループ化
- 3ー1.集合関数(SUM、MAX 他)
- 3ー2.グループ化(Group by)
- 3ー3.グループ化したテーブルの抽出条件付加(Having)
- 4.値を上下限の範囲で抽出(Between)
- 5.文字パターンで抽出(Like)
- 6.重複行の排除(Distinct)
- 7.テーブルの結合
- 7-1.内部結合
- 7-1-1.Inner Joinを使う方法
- 7-1-2.Where句を使う方法
- 7-2.外部結合(Outer Join)
- 7-2-1.一方のテーブルのデータを抽出
- 7-2-2.一方のテーブルのみのデータを抽出
- 8.データの変更
- 8-1.行挿入(Insert)
- 8-2.データ変更(Update)
- 8-3.行削除(Delete)
- アプリ実例
例えば入出庫データを記録する場合、図01の左側の様に「全項目を1つにした表」を作る事が多いと思います。

図01
紙の台帳やExcelの手入力のワークシートならば、この様な作り方でも良いと思います。しかしリレーショナルデータベースでのテーブルは、大切なデータを守るため「テーブル内では、同じデータを二重に持たない」事を目標にし、図01の右側の様に「単機能」のテーブルを複数作ることが一般的です。
「データを守る」とは、例えば台帳上の品名を「いちご」から「ストロベリー」に変更する必要が出てきた時、図01の左側の様な大きなテーブルでは「データを複数行に渡って操作」する必要があります。上から順に書き換えて最終行まで成功すれば良いのですが、もしトラブルにより書き換えが途中で止まってしまった時は、「いちご」と「ストロベリー」が混在したテーブルが出来てしまいます。
しかし、単機能のテーブルの場合は、品名テーブル(図01の一番右側)のデータを「1箇所だけ」書き換えればOKとなります。このように、単機能テーブルにすることで「失敗するリスクを非常に低く」することができます。
しかし各テーブルはバラバラなのでは無く、図01の下側に矢印で示したように「それぞれのテーブルが他のテーブルの1つの列で重なる」ことで、各テーブルが「関連付け(=リレーショナル)」られる事になります。
リレーショナルデータベースに対する処理は全てSQL(Structured Query Language:構造化問い合わせ言語)を使いますが、1つのテーブルのデータを単に操作するだけでなく、上記のような「単機能テーブル」を結合して「目的とするデータ項目を一気に取り出す」ことも可能です。
今回は、テーブルの結合を含めた「データを操作するSQL」について簡単に説明します。
尚、図01では説明のためにテーブルをバラバラにしていますが、実際には「正規化」という考え方に沿って作業します。また、正規化を行わない(=大きなテーブルのまま)場合もあります。
また以下の説明で出てくるテーブルは、「Num列」と「St列」を持つテーブルで、図01で言えば「入庫テーブル」や「出庫テーブル」のようなものだと思って下さい。
1.データの抽出
1-1.列内の値を検索
単一テーブルや結合したテーブル(テーブルの結合で説明)から行(レコード)を抽出するためにはSelect文を使い、From句の後ろにテーブル名を指定します。そして目的の行を抽出するために、Where句に続けて「抽出の条件式」を記述します。条件式はExcelのIf文等と同様に、検索したい列名と検索値を「=」「>」「<」の記号で繋ぎます。なお数値を検索値とする場合は、図02のように「where Num > 1」と数値を直接記述しますが、文字列の場合は「where St = 'A1'」のように、文字列を「'(シングルクォーテーション)」で囲みます。Excelの場合の「"(ダブルクォーテーション)」とは異なりますので注意が必要です。
1-1-1.全ての列のデータを抽出
抽出した行の「全ての列のデータ」を出力する場合は、Select に続く列指定を「*(アスタリスク)」とします。図02「Select * from A where Num > 1」の場合だと、テーブルAには「Num列」と「St列」がありますので、その2列分すべてが表示されます。
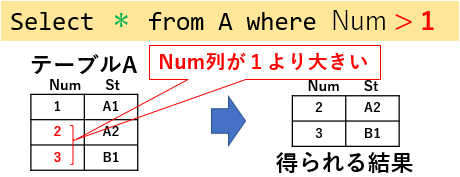
図02
なお、Where句なしの「Select * from A 」とすると、テーブルの「全ての列 × 全ての行」のデータが得られる事になります。
1-1-2.特定の列のデータを抽出
抽出した行の「特定の列のデータ」を出力する場合は、図03「Select St from A where Num > 1」のように、Select に続けて「出力する列名」を記述します。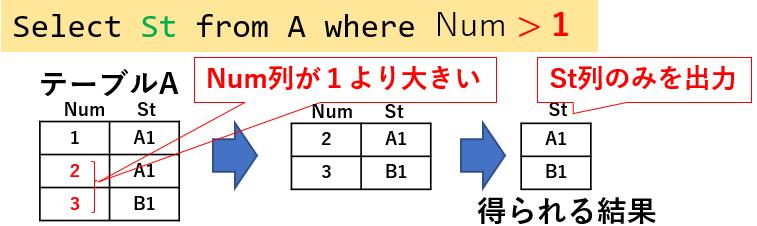
図03
複数の列を出力したい場合は、カンマ区切りで「Select Num,St from A ・・・」のように列記します。
なお、列指定と「*(アスタリスク)」を同時に使用することは出来ません。
1-1-3.抽出されたデータの加工
出力時されるデータに加工を加える場合は、指定列に対して「算術式」が使用できます。図04「Select Num * 10 from A where St='A1'」では、Num列を「Num * 10」とすることで、抽出した値の10倍の値を出力します。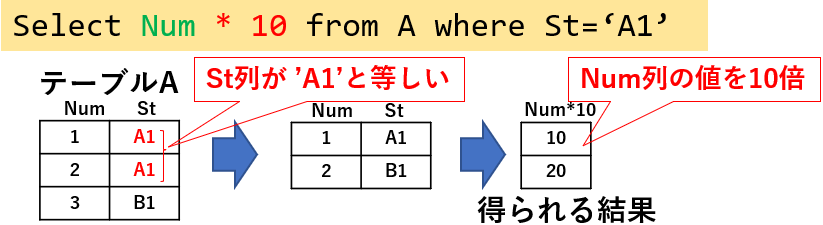
図04
使用できる算術式として「+(加算)」「-(減算)」「*(乗算)」「/(除算)」は、どのデータベースでも使用できます。また個々のデータベース特有の便利な演算子もありますが、使用するデータベースが変わる可能性がある場合には、多用は控えた方が良いと思います。
なお、文字列の列(例えば図04ではテーブルAのSt列)に対しては、「+」を使っての文字列結合が可能です。例えば「Select St + '番' from A where Num > 2」等とすれば、「B1番」という結果が得られます。
1-1-4.ヌル値の扱い
ヌル値を対象として絞り込む場合、SQLでは「列名=Null」のような値比較は使えません。ヌルは「まだ決まっていない値」ですので通常の「等号・不等号」が使えないのです。使用する場合は図05「Select * from A where St is not Null」のように、条件式を「St is not Null」とすることでヌル以外の行が抽出できます。
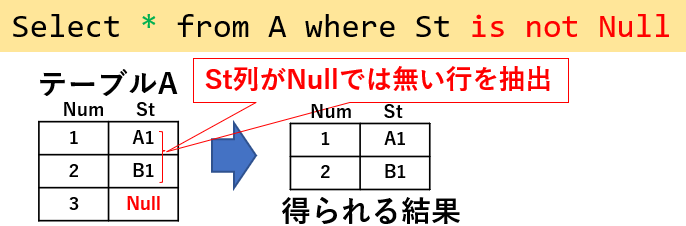
図05
逆に「Select Num from A where St is Null」とすると「St列がヌル」のレコード(図05で言えば「3」)が抽出されます。
1-2.複数の条件式
条件式をつなげるときは、Excelと同様に「AND」や「OR」を使用します。図06「Select * from A where Num > 1 and St='B1'」では「Num > 1」と「St='B1'」の2つの条件の両方を満足する行を抽出しています。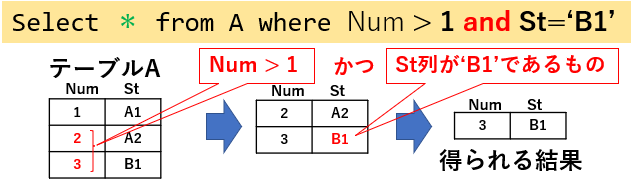
図06
また条件式にはカッコが使用でき、カッコ内を優先して絞り込んでくれます。
なお、AND・ORを含めた優先度は、括弧内の条件式 > ANDで接続された条件式 > ORで接続された条件式 です。
1-3.複数の値と合致するデータの抽出
列内の値を「複数の値」と比較するには「in」を使用し、その後に続くカッコ内にカンマ区切りで値を列挙します。列挙した値のどれかと合致する場合に、行が抽出されます。図07「Select * from A where St in ('A1','A2')」では、'A1'か'A2'のどちらかと合致している行を抽出しています。
また、列挙する代わりに「単列の値が得られるSQL文(サブクエリー、副問い合わせ)」を記述することも可能です。
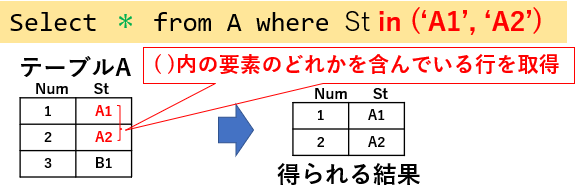
図07
逆に、複数の値に対し「どの要素も含んでいない」データを抽出する場合は「not in」を使用します。図08「Select * from A where St not in ('A1','A2')」では、'A1'でも'A2'でも無い行を抽出しています。
後ろに続くカッコ内は「in」の場合と同じで、「副問い合わせ」の記述が可能です。
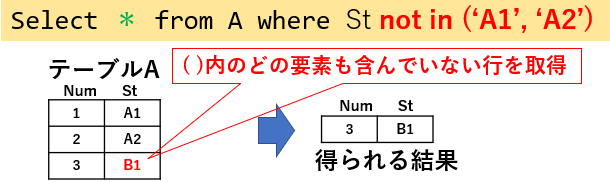
図08
2.並べ替え
抽出したデータを出力する際、その出力順序を指定することが可能です。「order by」句の後ろに並び変える列名を記述します。図09「Select * from A order by Num Desc」では、Num列を降順で出力しています。
なお、Descを付けると逆順(降順)になり、Ascを付けるか又は何も付けないと正順(昇順)になります。
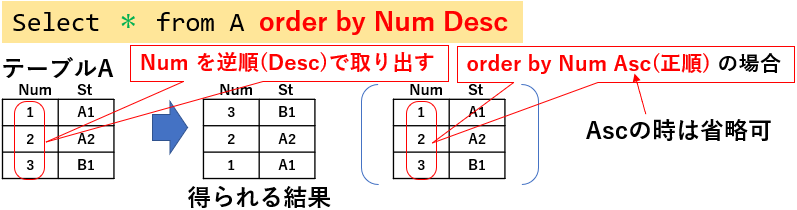
図09
Order by句の後ろには、複数の列名を列記できますが、Order by句に近い方が並び替え優先度が高くなります。例えば「Select * from A order by Num,St 」とすれば、Numが第一優先、Stが第二優先になります。
データベース内のデータは、Excelのワークシートみたいなイメージで紹介されていますが、出力順は「基本的にランダム」です。Insert順の様に見える場合もあるとは思いますが、出力順が重要な場合には必ず「order by句」を指定します。
3.集合関数とグループ化
3ー1.集合関数
抽出した列の値に対し、最大・最小などの様々な集計をして出力する事が可能です。図10「Select Max(Num) from A」では、「MAX」という集合関数を使用し、抽出した値の内で最大値のものを出力しています。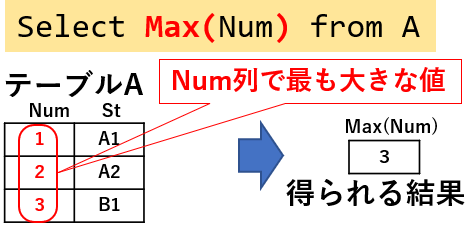
図10
使用できる集合関数は、主に「SUM(合計)」「MAX(最大値)」「MIN(最小値)」「AVG(平均値)」「COUNT(データの個数)」です。これらは、どのデータベースでも使用できそうです。データベースの種類によってはこれ以外の集合関数を持っているものもあります。
3ー2.グループ化
テーブルの行を「Group by」句を使って「指定した列でグループ化」することが出来ます。図11「Select SUM(Num),St from A Group by St」では、St列を「同じ値同士でグループ化」しています。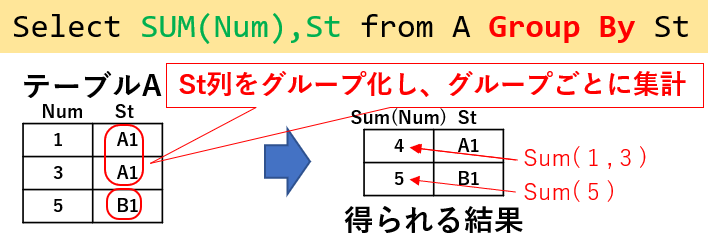
図11
グループ化する事は理解できると思いますが、グループ化をせず、且つ出力する列(図11だとNum列)には「各行に異なる値が入っている(図11では、'A1'でSt列をグループ化しようとしているのに、Num列には1と3がある)」ので、Num列はそのままではグループ化できません。
そこで、グループ化しなかった列に対しては「集合関数」を使用し、「グループ化された代表値」のような位置づけで「1つの値のみ」が得られるようにします。図11では、その集合関数にSUMを使用しています。
もし「グループ化されていないけど、出力する列は全部同じ値」だとしても、集合関数を使用しないとエラーになります。
3ー3.グループ化したテーブルの抽出条件付加
「グループ化」したテーブルに対して、抽出条件を使って絞り込むのが「Having」です。図12「Select SUM(Num),St from A Group by St Having Sum(Num) < 5」では、図11でグループ化したテーブルに対し、Sum(Num)列が5未満の行を抽出しています。
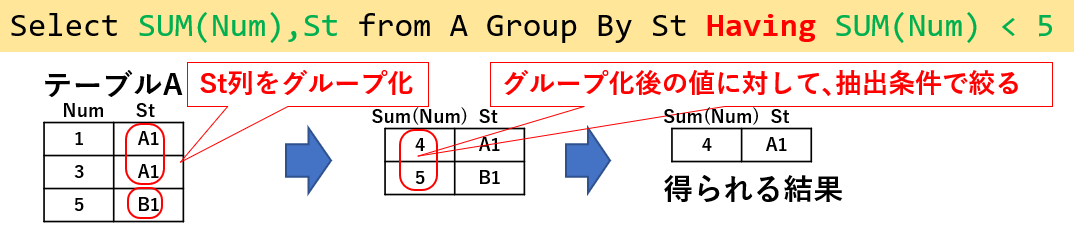
図12
4.値を上下限の範囲で抽出
上下限値を使って、範囲で絞り込むには「between 下限値 and 上限値」を使用します。図13「Select * from A where Num between 1 and 2」では、1(以上)且つ 2(以下)の行を抽出しています。
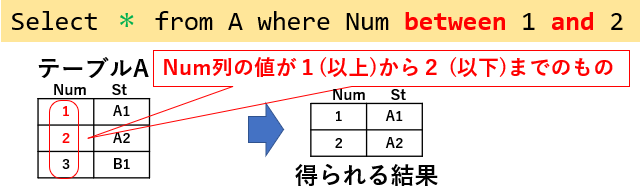
図13
この「Select * from A where Num between 1 and 2 」を「複数の条件式」で記述すると「Select * from A where 1 <= Num and Num <= 2 」となります。
このbetweenの否定で「not」を付けて「not between 下限値 and 上限値」とすると、「(下限値以上~上限値以下)の範囲以外」を抽出します。
なお「下限値と上限値とを、逆には記述できない」と説明しているサイトもありますが、例えばAccessで試してみるとちゃんと同じ結果が得られます。しかし、データベースの種類によってはエラーが発生する場合も考えられますので、逆に記述する事は避けた方が良いと思います。
また、下限値か上限値かのどちらかがNullになると、必ず「何も抽出されない」状態となります。
5.文字パターンで抽出
含まれる文字列から抽出するには「like」演算子を使用します。図14「Select * from A where St like '%A%'」では、St列内から「'A'という文字列を含む行」を抽出しています。
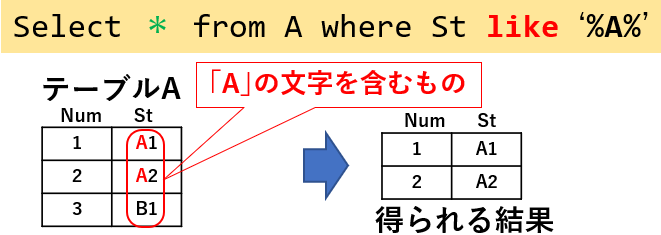
図14
なお図14では「like '%A%'」と、'A'の文字列の前後に「%(パーセント)」を付けていますが、この「%」は「ゼロ文字以上の任意の文字列」の意味なので、「'A'という文字を含んでいる文字列」を抽出することになります。
なお、SQLで使用できるワイルドカードは以下の2つです。
「%(パーセント)」 :0文字以上の任意の文字列
「_(アンダースコア)」:1文字の任意の文字
ですので「like 'A%'」とすれば「'A'で始まる文字列」、「like '_A%'」とすれば「2文字目が'A'の文字列」となります。
検索文字の1つとして「%」や「_」を使う場合は、そのワイルドカードをエスケープする必要があります。
一般的にはESCAPEキーワードを使って「Select * from A where St like '%!_%' ESCAPE '!' 」とすると、「_(アンダースコア)」を含む文字列が抽出されます。
但しAccessでは、このESCAPEキーワードが使えないため、ワイルドカードを角カッコで囲み「Select * from A where St like '%[_]%' 」とすることが必要です。
なお「Select * from A where St like '%[A]%'」などと、エスケープ文字以外でも使用できますので、Accessでは常に角カッコを付けておくのも良いかもしれません(他のデータベースでは、どういう扱いになるのかは未調査です)。
また「like」演算子にも「not」が使え、例えば「Select * from A where St not like '%A%'」とすることで、「'A'を含まない文字列」を抽出することができます。但し「'A'を含まない」と言っても、Nullは対象外となり抽出されません。
6.重複行の排除
抽出されたデータの「重複行を排除」して出力するのが「Distinct」キーワードです。図15「Select Distinct St from A」では、St列で重複している「'A1'」を1つだけ出力しています。
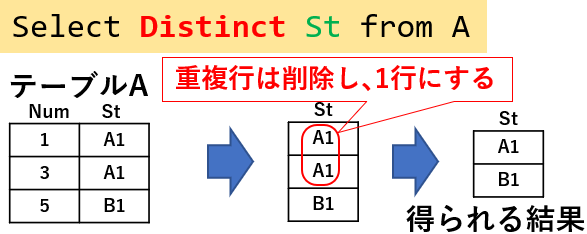
図15
なお「Select Distinct Num,St from A」と複数列の出力を指定すると、「Num列とSt列のセット」で重複しないデータが出力されます。つまりNum列の出力データ、St列の出力データだけを見ると、同じデータがある場合があります。
7.テーブルの結合
リレーショナルデータベースでは、正規化したテーブル同士を結合し、見かけ上「大きなテーブル」としてレコードを抽出する場面が多くあります。結合には「内部結合」と「外部結合」があります。7-1.内部結合
2つのテーブルを結合する方法の1つが「内部結合」です。図16の左端のベン図のように、テーブルの重なった部分を得ることのできる結合方法です。内部結合の手法には2種類あります。7-1-1.inner joinを使う方法
手法の1つ目は「inner join」を使う方法です。図16「Select * from A inner join B on A.St=B.St」では、テーブルAとテーブルBをSt列で内部結合しています。
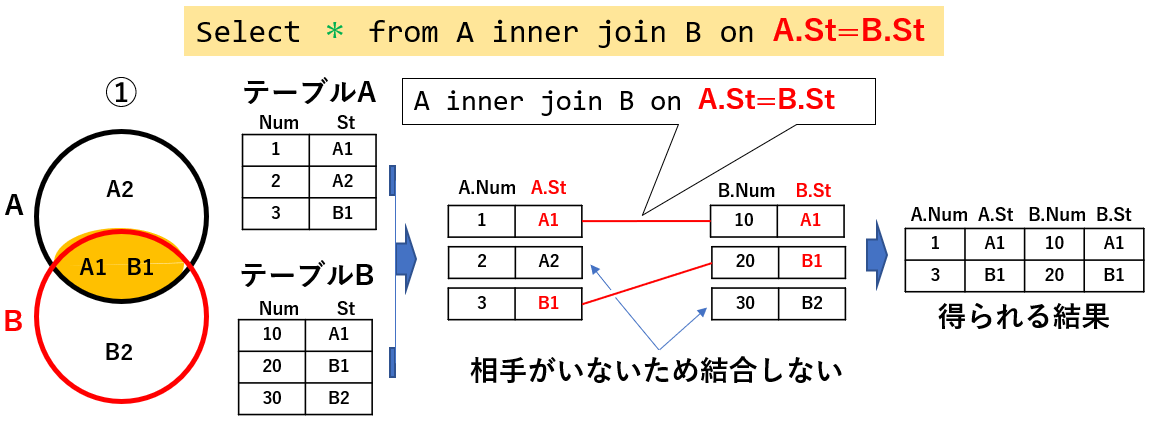
図16
図16では、同種類のデータ(例えば、倉庫の棚番号)の列 St を持つテーブルAとテーブルBを結合し、A,Bのどちらのテーブルにも存在するSt値を取り出しています。
「on」の後ろの「A.St = B.St」が結合条件になり、テーブルA側のSt値とテーブルB側のSt値が等しい行を結び付けます(図16の赤い結合線)。片方のテーブルにしかない値を持つ行は、内部結合の対象からは外れます。
なお「A.St」とは、「テーブルAのSt列」という意味になります。
出力列を「Select * from A ・・・」と、「*(アスタリスク=全ての列)」指定していますので、テーブルAとテーブルBのそれぞれ2列全てが出力(図16の一番右側)されています。
これを例えば「Select A.St from A ・・・」とすると、「テーブルAのSt列」だけが得られることになります。
なお「St値は同じ値」だからと考えて、テーブル名を指定せずに「Select St from A inner join B ・・・」などとしてしまうと、SQLとしては「Select の後ろの St が、どのテーブルの列名なのか」かが判断できないため「エラー」になります。複数のテーブルを指定するSQL文では、必ず「テーブル名を指定」する必要があります。
7-1-2.where句を使う方法
手法の2つ目は「where句で結合条件を与える」方法です。図17「Select * from A ,B where A.St=B.St」では、テーブルAとテーブルBをSt列で内部結合しています。
図16と結果は同じですが過程が異なります。
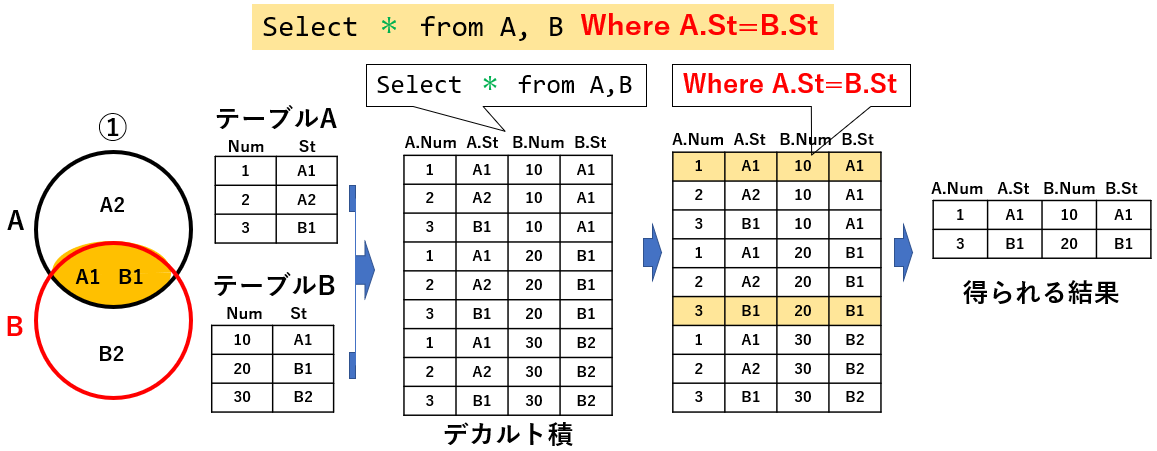
図17
まず、途中までの「Select * from A,B」という部分では、テーブルAとテーブルBの全ての行の組み合わせを求めています。数学用語では「デカルト積」とか「直積」と呼ばれているようです。
そのデカルト積の表に対して「Where A.St = B.St」の抽出条件を与えますので、「A.St の値と B.St の値が同じ行(図17のオレンジ色に塗られた行)」だけが抽出されることになります。
SQLの実行中に、データベース内部(メモリー上)でデカルト積を実際に作るのかは分かりませんが、他サイトでは「行の多いテーブル同士の場合は無駄が多い」とか「結合条件をWhereで与えるのは古い書き方」とのコメントがありますので、内部結合の場合は図16の「inner join ~ on」の記述法をお勧めします。
7-2.外部結合
外部結合は「一方のテーブルのデータを抽出する方法」です。7-2-1.一方のテーブルのデータを抽出
まず、図18の左端のベン図のような状態にするには「outer join ~ on」を使用します。図18「Select * from A Left outer join B on A.St=B.St」では、テーブルAに対してテーブルBを外部結合しています。
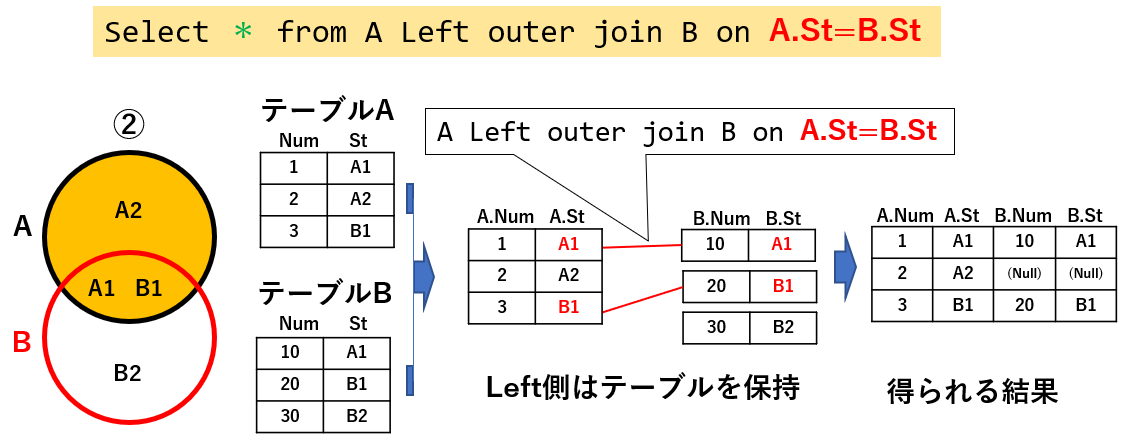
図18
まず外部結合では、2つのテーブルの内、どちらを「軸のテーブル」にするかを決めます。例えば図18のベン図の場合、オレンジ色に塗ったテーブルAを軸にするのであれば「 A Left outer join B 」又は「B Right outer join A」とします。
つまり「Left」であれば「左側に記述したテーブル」、「Right」であれば「右側に記述したテーブル」が軸となります。
軸となるテーブルからは全ての行が得られ、「onの後ろに続く結合条件」に従って「軸では無いテーブル」の行が「軸テーブル」の行に結合されます。図18では「on A.St = B.St」となっていますので、A・BテーブルのSt列の値を比較して同じであれば結合します(赤い結合線)
一方「on A.St = B.St」が成立しない行(図18ではテーブルAの2行目)については相手がいないわけですから、「値が未定」という意味の「Null」が入ります。
「これだと、Select * from A と何が違うの?」と思われる方もいるかもしれません。違うのは「テーブルBの情報(列)もテーブルAに取り込める」ことです。図18のテーブルA・Bで言えば、テーブルBのNum列の情報が結合できるのです。
7-2-2.一方のテーブルのみのデータを抽出
図18の外部結合を細工すると「一方のテーブルのみのデータを抽出」することが可能です。図19左端のベン図の状態です。図19「Select * from A Left outer join B on A.St=B.St where B.St is Null」では、テーブルAに対してテーブルBを外部結合し、テーブルBの情報の無いもの(テーブルAの情報のみがあるデータ)を抽出しています。
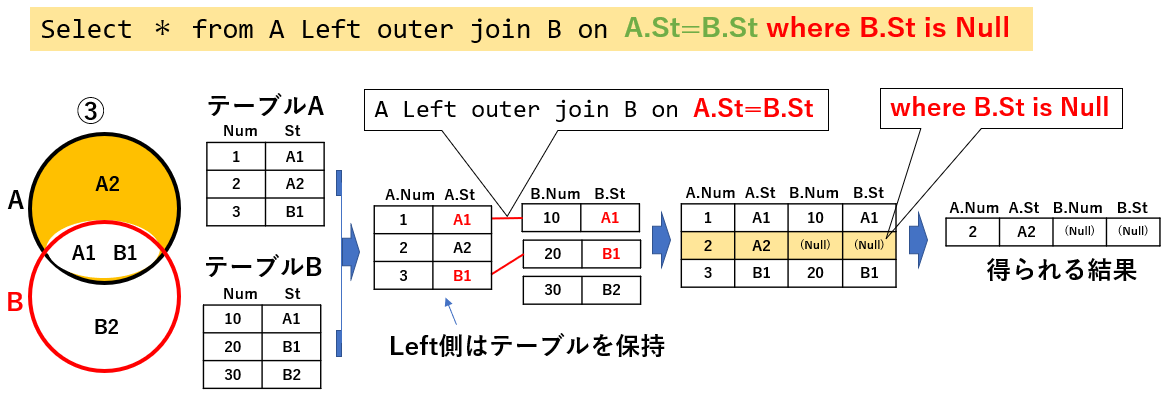
図19
図18の時に得られた結果では、2番目のデータはテーブルBに含まれていませんのでテーブルBの情報がNullになっています。このNullであることを使い「Where B.St is Null 」を追加することで、「一方のテーブルのみのデータを抽出」することが出来ます。
8.データの変更
8-1.行挿入(Insert)
テーブルに新しい行としてデータを挿入するには「Insert into ~ values」を使用します。図20「Insert into A(Num,St) values(4,'B3')」では、Num列に値「4」を、St列に値「'B3'」を行挿入しています。
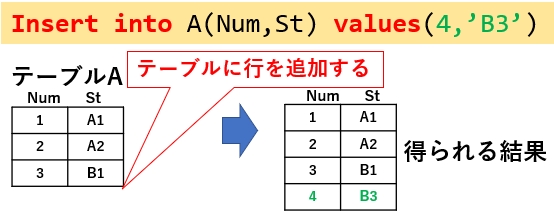
図20
一般のデータベースでは列のデータ型を決めることが出来ますので、数値列に文字列を挿入しようとしても制限が掛かります。
一方Excelのワークシートをデータベースにする場合は、混載は可能になってしまいます。いずれにしても、データの挿入前には、データ型をチェックする工程が必要です。
8-2.データ変更(Update)
既存のデータを変更するには「Update ~ set」を使用します。図21「Update A set Num=4 ,St='B3' where Num=1」では、Num列が「1」の行に対し、Num列を値「4」に、St列を値「'B3'」に変更しています。Num列が「1」の行が複数あれば、その全ての対象行のデータを書き換えます。
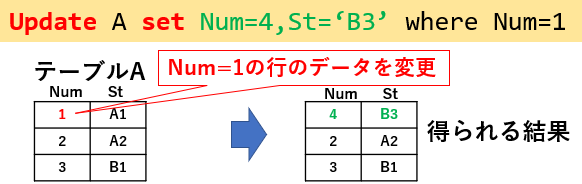
図21
この時にWhere句を付け忘れたりすると、全データが書き換えられてしまいます。充分注意して下さい。
(Excelに備わっている「元に戻す」処理では戻せません。)
8-3.行削除(Delete)
データを削除する場合は「Delete」を使用します。図22「Delete from A where Num=1」では、Num列が「1」の行を削除します。Num列が「1」の行が複数あれば、その全ての対象行を削除します。
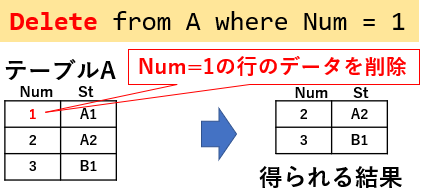
図22
削除する行はWhere句で抽出しますが、Where句を省略する(≒忘れる)とテーブルの全データが削除されます。充分注意が必要です。
なお、「Excelワークシート」や「CSVファイル」をデータベースのテーブルとして使う場合には、このDelete文は使用できません。その様なシステムでは、データ列とは別のDEL列を作り「削除した事が分かる値」を入れるとか、1行分のデータを全てクリアする ような工夫が必要です。
但しDEL列を作った際にはSelect文でDEL列を選択しないように「Where Del is Null」を抽出条件に追加したり、行クリアした時にもクリア行を選択しないような工夫を併せて行うことが必要です。
アプリ実例
「Excelシート上にDBを作り、SQLを使ってデータを入出力する」「ExcelシートDBとSQLを使った会議室予約システム」
「CSVファイルの読み込み」
「ExcelシートDBとSQLを使った倉庫管理システム」
「アンケートの回収と集計方法」
「共有資料の登録と閲覧ができるサーバーシステム」
「複数の備品を同時予約可能な貸出台帳」
「ExcelからAccessデータベースを作成・操作」
「Accessデータベースを使用した売上台帳」
「設備の稼働状態を入力し、グラフで確認」
「PCの固有情報の取得」